處理 CSV 檔案

什麼是 CSV?
CSV,全名為 Comma Separated Values,是一種常見的資料格式。對有使用過 Excel 的人來說應該不陌生,如果你的電腦有安裝 Excel 軟體的話,很有可能用滑鼠點兩下 CSV 檔案就會直接用 Excel 開啟,還會自動展開成試算表的樣子。不過 CSV 並不是 Excel 試算表,它是純文字檔案格式,用一般的文字編輯器都能開啟,每一行代表一筆資料,也正如其名,每一行資料通常是以逗號(Comma)做為分隔字元,它看起來的樣子可能像這樣:
id,name,gender,age,hero_level,hero_rank,description
1,龍卷,F,28,S,2,"女性英雄, 與實際年齡不相稱"
14,傑諾斯,M,19,S,17,"生化人, 外形俊朗,實力強大, 但在戰鬥關鍵時刻總是鬆懈大意"
35,埼玉,M,25,C,388,"故事的主角, 職業是英雄, 無論多強的敵人幾乎都是一拳擊敗"
也許你會好奇,在上一章不就介紹過檔案的讀寫了嗎?為什麼還需要多這個章節來介紹 CSV 呢?雖然 CSV 格式說是用逗號分隔沒錯,但由於缺少一個完善的標準,所以由不同的應用程式所匯出的 CSV 格式可能都會有一些不同,也就是所謂的「方言(dialect)」或是「一個 CSV,各自表述」,例如有些會用 Tab 或是 | 做為分隔符號。不只這樣,同樣是換行,不同的作業系統上可能會有不同的表示方式,例如 Windows 是使用 \r\n,而 Linux 則是 \n。這些方言之間的差異,排列組合算一算也不少種,處理起來也是有一點麻煩。
讀取 CSV 檔案
我們先用上一章學到的讀檔手法來讀取一個 CSV 檔案:
with open('heroes.csv') as f:
for row in f:
cols = row.strip().split(',')
print(cols)
這裡我先使用字串的 .strip() 方法去掉每行的換行符號,然後再接著用字串的 .split() 方法將每行的資料透過逗號拆成一個串列,處理之後的結果看起來像這樣:
['id', 'name', 'gender', 'age', 'hero_level', 'hero_rank', 'description']
['1', '龍卷', 'F', '28', 'S', '2', '"女性英雄', ' 與實際年齡不相稱"']
['14', '傑諾斯', 'M', '19', 'S', '17', '"生化人', ' 外形俊朗', '實力強大', ' 但在戰鬥關鍵時刻總是鬆懈大意"']
['35', '埼玉', 'M', '25', 'C', '388', '"故事的主角', ' 職業是英雄', ' 無論多強的敵人幾乎都是一拳擊敗"']
像這樣手工拆解也能讀到資料,但如果資料中有逗號或換行符號可能會拆出不正確的結果,例如把說明文字的逗號也拆開了,而裡面的引號也處理的不太好。
我相信聰明如你,再繼續寫幾行程式碼來處理這些細節一定難不倒你,但這樣一�來程式碼可能會變得有點複雜,萬一之後還有其他的特殊情況還得再加更多額外的規則來處理。Python 內建的 csv 模組提供了一些便利的方法來處理這些麻煩,讓我們可以更簡單的讀取和寫入 CSV 檔案。
假設我的 CSV 檔名叫做 heroes_v1.csv:
import csv
with open('heroes_v1.csv') as f:
reader = csv.reader(f)
for row in reader:
print(row)
csv 模組裡的 reader() 函數可以自動幫我們處理逗號和換行符號,而且還會知道有些文字裡的逗號不用拆,執行之後的結果看起來像這樣:
['id', 'name', 'gender', 'age', 'hero_level', 'hero_rank', 'description']
['1', '龍卷', 'F', '28', 'S', '2', '女性英雄, 與實際年齡不相稱']
['14', '傑諾斯', 'M', '19', 'S', '17', '生化人, 外形俊朗,實力強大, 但在戰鬥關鍵��時刻總是鬆懈大意']
['35', '埼玉', 'M', '25', 'C', '388', '故事的主角, 職業是英雄, 無論多強的敵人幾乎都是一拳擊敗']
這看起來好多了。
csv 模組的 reader() 函數有一些參數可以設定,例如 delimiter 可以指定分隔符號,它的預設值就是 ,;quotechar 可以指定引號符號,它的預設值剛好就是 ",skipinitialspace 可以設定是否忽略空白等等。
設定方言
剛才使用的 csv.reader() 函數裡有個參數可以指定使用哪一種「方言(dialect)」,方言是 CSV 檔案的格式描述,例如要用什麼符號當做為分隔符號、引號符號是什麼等等。
csv 模組有內建幾個常見的方言:
>>> import csv
>>> csv.list_dialects()
['excel', 'excel-tab', 'unix']
如果沒有特別指定的話,csv.reader() 函數預設的方言是 excel,就是用逗號當做分隔符號,並使用 " 做為引號。
如果 CSV 檔案的內容不是使用逗號而是用 | 符號來分隔,像這樣:
id|name| gender|age|hero_level|hero_rank| description
1|'龍卷'| F|28|S|2| '女性英雄, 與實際年齡不相稱'
14|'傑諾斯'| M|19|S| 17| '生化人, 外形俊朗,實力強大, 但在戰鬥關鍵時刻總是鬆懈大意'
35|'埼玉'|M| 25|C|388| '故事的主角, 職業是英雄, 無論多強的敵人幾乎都是一拳擊敗'
不只把逗號換成了 | 符號,而且還多了一些空白,我們在可以給 csv.reader() 函數指定一些參數:
import csv
with open('heroes_v2.csv') as f:
reader = csv.reader(f, delimiter='|', quotechar="'", skipinitialspace=True)
for row in reader:
print(row)
加上這些參數之後,解析出來的結果就跟之前的一樣了。如果我們很常使用這種格式的話,每次都要設定這麼多參數也是有點累,除了內建的三種方言之外,我們也可以註冊自己的方言:
import csv
csv.register_dialect(
'hero_v2',
delimiter='|',
quotechar="'",
skipinitialspace=True
)
register_dialect() 函數的第一個參數是方言的名字,接下來就是設定這個方言所使用的參數。註冊完成之後,就可以帶到 csv.reader() 裡使用了:
with open('heroes_v2.csv') as f:
reader = csv.reader(f, dialect='hero_v2')
for row in reader:
print(row)
寫入 CSV 檔案
csv 模組的 reader() 函數可以讀取 CSV 檔案,如果是要寫入 CSV 檔案,在同一個模組裡的 writer() 函數可以幫我們搞定這件事。如果前面的 reader() 有看懂的話,writer() 用起來也滿簡單的:
import csv
with open("my_heroes.csv", "w") as f:
writer = csv.writer(f)
# 寫入標題
fields = ["id", "name", "gender", "age", "hero_level", "hero_rank", "description"]
writer.writerow(fields)
writer.writerow(["1", "龍卷", "F", "28", "S", "2", "女性英雄, 與實際年齡不相稱"])
writer.writerow(["14", "傑諾斯", "M", "19", "S", "17", "生化人, 外形俊朗,實力強大, 但在戰鬥關鍵時刻總是鬆懈大意"])
writer.writerow(["35", "埼玉", "M", "25", "C", "388", "故事的主角, 職業是英雇, 無論多強的敵人幾乎都是一拳擊敗"])
在開啟檔案的時候需要把檔案模式改成 w 或 a 才能寫入檔案,接下來 csv.writer() 函數如果沒加額外的設定的話,跟 reader() 函數一樣預設使用 excel 當做方言。
要寫入的時候,可以呼叫 writer 物件身上的 .writerow() 方法,一次寫入一行資料。如果想要寫入多行的話,可使用迴圈多次呼叫 .writerow() 方法,或是直接呼叫 .writerows() 方法,把所有的資料一次寫入:
data = [
["1", "龍卷", "F", "28", "S", "2", "女性英雄, 與實際年齡不相稱"],
["14", "傑諾斯", "M", "19", "S", "17", "生化人, 外形俊朗,實力強大, 但在戰鬥關鍵時刻總是鬆懈大意"],
["35", "埼玉", "M", "25", "C", "388", "故事的主角, 職業是英雇, 無論多強的敵人幾乎都是一拳擊敗"]
]
writer.writerows(data)
剛剛我們學到的客制化方言也可以用在 writer() 函數:
writer = csv.writer(f, dialect="hero_v2")
這樣就可以用我們自己註冊的方言來寫入 CSV 檔案了。
《練習》台積電股價 K 線圖
我從台灣證券交易所的網站下載了一個 CSV 檔案,裡面記錄了台積電(2330)於 2024 年 5 月的股價成交資訊,待會我們會用 Python 寫一些程式來解析這個檔案的內容,並且畫出 K 線圖。K線圖,又稱蠟燭圖(Candlestick Chart),是股票分析中常用的技術分析工具。如果你不知道什麼是 K 線圖,別擔心,我也不知道,我們一起來學怎麼畫。
資料來源的話,你可以自行到證交所網站下載一份你感興趣的股價交易資料,或是也可以從本書的 GitHub 下載。
- 台灣證券交易所 https://5xcamp.us/stock-day
- CSV 檔案下載 https://5xcamp.us/stock-202405-csv
我下載回來的 CSV 檔名是 STOCK_DAY_2330_202405.csv,待會的程式範例也會用這個檔名。首先,如果你用文字編輯器打開這個檔案的話,也許會看到一些亂碼,這是因為我從證交所網站下載的檔案就是用 Big5 方式編碼,所以待會用 open() 函數開檔的時候需要指定編碼方式。更多關於文字編碼的故事可往前翻閱數字與文字章節的介紹。
你也許會好奇為什麼這個檔案不是使用現在比較普及的 UTF-8 編碼,嗯...這個問題我不好說,這得去問證交所的工程師才會知道。但不管是 UTF 還是 Big5 編碼,既然編碼都編了,我們就暫時接受這個事實,先試著讀取這個檔案看看:
import csv
with open("STOCK_DAY_2330_202405.csv", encoding='big5') as f:
title = next(f).replace('"', "") # 標題
# 待會程式還會繼續寫...
記得在開檔的時候指定 encoding='big5',不然執行的時候會出錯。如果你有先偷看過這個檔案,應該會發現第一行寫著「113年05月 2330 台積電 各日成交資訊」,這行對我來說不是我要的資料,但待會可以用來當做圖表的標題,所以我先用 next(f) 取得這一行之後再簡單處理一下引號。
接下來雖然可以使用剛才介紹的 csv 模組的 read() 函數,但同樣在 csv 模組裡有個更方便的函數叫做 DictReader(),它會用第一行的資料當作欄位名稱,並根據這個欄位把剩下的每一行資料轉換成字典,這樣就可以用欄位名稱來取得資料,而不是用索引值。
要畫 K 線圖會需要用到日期、開盤價、收盤價、最高價、最低價等資訊,所以我們只要先準備這些資料就好,其他的可暫時不理它:
import csv
with open("STOCK_DAY_2330_202405.csv", encoding='big5') as f:
title = next(f).replace('"', "") # 標題
data = csv.DictReader(f, restval=None)
for row in data:
if row['成交股數'] is not None:
date = int(row['日期'].split('/')[-1])
opening = int(float(row['開盤價']))
closing = int(float(row['收盤價']))
highest = int(float(row['最高價']))
lowest = int(float(row['最低價']))
# 待會要寫繪��圖程式
簡單的判斷一下,只要當天有「成交股數」的資料的話,就抓出日期、開盤價、收盤價、最高價、最低價這幾個欄位的數字,順便做一下數字轉換。因為日期的格式是 "113/05/01",但我只想要最後面的日數,所以這裡我使用字串的 .split() 方法做了些處理。接下來要畫 K 線圖,這裡我使用 matplotlib 套件來繪圖,如果你沒有安裝的話,可以使用 pip 來安裝:
$ pip install matplotlib
matplotlib https://matplotlib.org/
再來,K 線圖要怎麼畫?K 線圖的主要元素有幾個:實線、影線以及漲跌的顏色:
- 實線的長度是開盤價和收盤價的差值
- 影線的長度是最高價和最低價的差值
- 如果收盤價比開盤價高就是漲,顏色是紅色,反之就是綠色
我們可以寫一個函數來畫 K 線圖:
from matplotlib import pyplot as plot
def draw_candlestick(date, opening, closing, highest, lowest):
delta_open_close = closing - opening
delta_high_low = highest - lowest
# 設定漲跌的顏色
color = "red" if delta_open_close > 0 else "green"
bottom = opening if delta_open_close > 0 else closing
# 實線(開、收盤價)
plot.bar(date, height=abs(delta_open_close), bottom=bottom, width=0.6, color=color)
# 影線(最高、最低價)
plot.bar(date, height=delta_high_low, bottom=lowest, width=0.1, color=color)
函數會接收日期、開盤、收盤價、最高、最低價這幾個參數,然後計算出實線和影線的長度,並根據開盤價和收盤價的大小來設定漲跌的顏色。這裡我用了兩次的 .bar() 方法在同一個地方畫了兩條線,一粗一細兩條線疊在一起,看起來就有點像是 K 線圖了。或是你也可另外找其他更專門用來畫金融圖表的套件來畫,會畫的更專業。
接下來把這些東西都組合在一起就可以開始畫圖了:
import csv
from matplotlib import pyplot as plot
# ... 略 ...
with open("STOCK_DAY_2330_202405.csv", encoding="big5") as f:
title = next(f).replace('"', "") # 標題
data = csv.DictReader(f, restval=None)
for row in data:
if row["成交股數"] is not None:
date = int(row["日期"].split("/")[-1])
opening = int(float(row["開盤價"]))
closing = int(float(row["收盤價"]))
highest = int(float(row["最高價"]))
lowest = int(float(row["最低價"]))
draw_candlestick(date, opening, closing, highest, lowest)
plot.xlabel(title)
plot.show()
在最後設定一下 X 軸的標題,然後執行程式,就可以看到 K 線圖了:
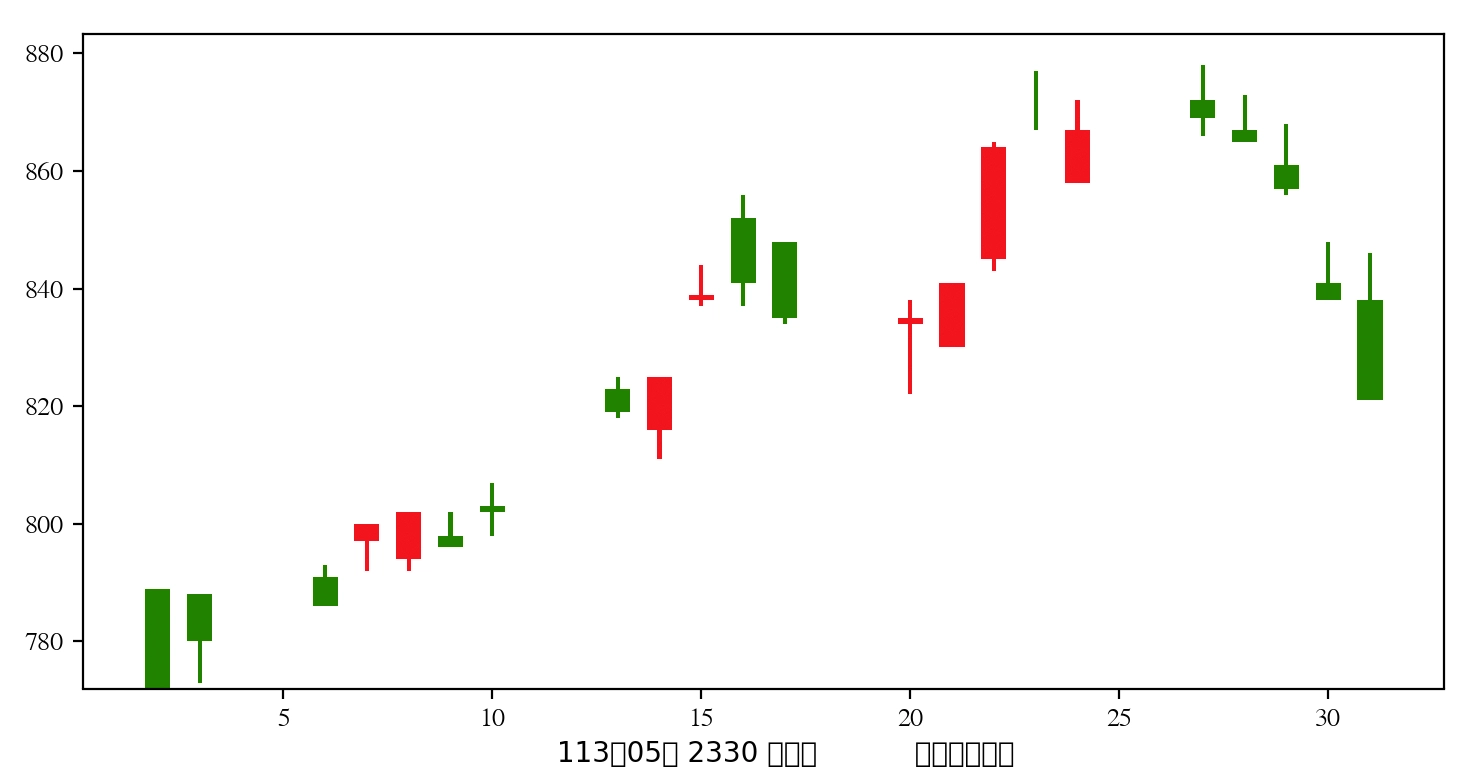
這樣就差不多完成了。不過執行之後應該會發現個小問題,就是中文字看起來怪怪的。因為 matplotlib 預設的字型只支援英文字型,不支援的字會變成方塊字,要正常顯示的話需要在設定中文字型:
with open("STOCK_DAY_2330_202405.csv", encoding="big5") as f:
title = next(f).replace('"', "") # 標題
# 設定中文字型(蘋果儷宋體)
plot.rc("font", family="Apple LiSung")
data = csv.DictReader(f, restval=None)
# ... 略 ...
我的電腦是 macOS,所以這裡使用的是「蘋果儷宋體(Apple LiSung)」,如果是 Windows 可以使用微軟正黑體或其他中文字型,這樣應該就可以正常顯示中文了:
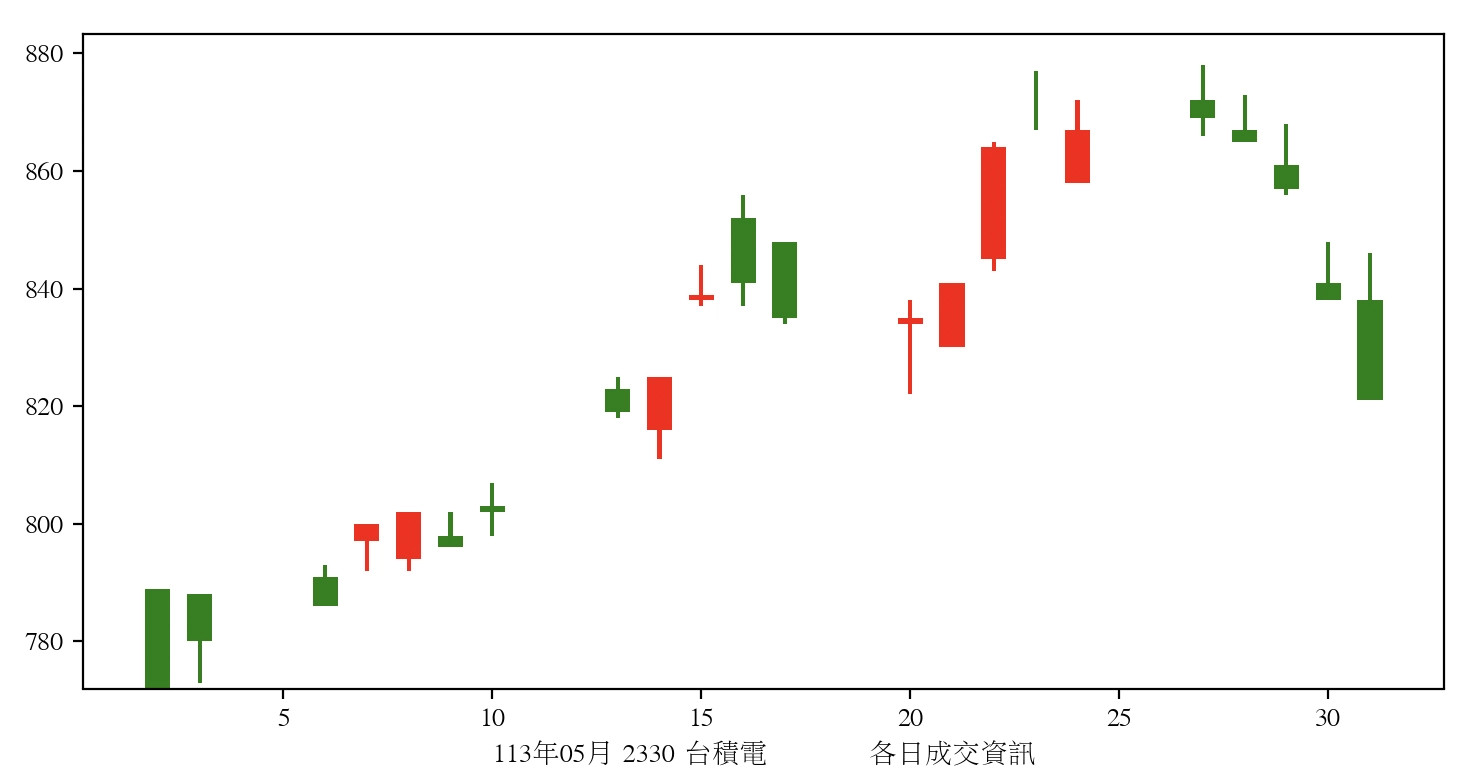
完整程式碼範例可於本書的 GitHub 取得。
題外話,年輕時候我天真的以為只要會看 K 線圖就可以發大財,但後來發現根本不是這麼回事,也因此繳了不少學費。投資一定有風險,基金投資有賺有賠,申購前應詳閱公開說明書。