串列

簡介
前面介紹到的資料型態,像是整數、浮點數、字串或是布林值,都是比較簡單的資料型態,除了這種比較單純的值之外,在 Python 有好幾種「集合」或「容器」型的資料結構,通常這些型式的資料結構都可以用來存放很多資料,在 Python 裡最常用的一種叫做「串列(List)」。串列是一塊連續的記憶體位置,你可以把這一堆連續的記憶體想像一個一個小格子,每個格子成有隔板隔開,有點像用來放藥的藥盒子,裡面可以放各式各樣的東西:
Photo by Laurynas
在介紹串列之前,大家有沒想過為什麼需要這種東西?一般的數字或字串不夠用嗎?在一般的場合是很夠用的,不過如果想要一口氣把一堆相同或類似的資料放在同一個變數裡,或是想把一堆資料傳給另一個函數的時候,這時候使用這種集合型的資料型態就會比較方便了。
在 Python 的串列寫起來像這樣:
heroes = ["悟空", "鳴人", "魯夫"]
score = [10, 30, 50]
串列的外層是一對中括號,裡面的東西通常會稱它為「元素(Element)」,每個元素之間使用逗號分開。看到這裡,如果各位曾經接觸過其他程式語言,大概會認為「這不就是『陣列(Array)』嗎?怎麼到了 Python 就改叫串列了?」
若以使用的手感來看,串列的確是很像陣列沒錯,你也可以把它當成陣列基本上不會出什麼亂子,甚至已經寫了一陣子的 Python 工程師朋友也不一定能講出這之間有什麼差別。它們雖然形狀看起來很像、用起來也很像,不過在本質上還是有些差異,並不是只有稱呼不同而已,在本章最後的冷知識會有比較詳細的補充說明。
陣列跟串列同樣都是一塊連續的記憶體位置,某些程式語言的陣列(例如 C 語言或 Rust),裡面存放的東西規定必須要是相同型別,要放字串就全部都放字串,要放數字就只能放數字,甚至整數跟浮點數還不能混著放,有的更嚴格的甚至是陣列一經宣告就不能再增加元素的也有。而在 Python 的串列沒有管這麼嚴格,串列裡你想放什麼都可以:
heroes = ["悟空", "鳴人", "魯夫"]
something = [1, True, None, 3.14, "python", heroes, [1, 2, 3]]
想放字串、數字、布林值都行,放個空值 None 也行,或是在串列裡面再放一層串列都��沒問題,想怎麼放就怎麼放。
串列常見操作
有幾個元素?
先從最簡單的操作開始,先來試著印出串列裡有多少顆元素,Python 有個內建函數 len() 可以做這件事:
>>> heroes = ["悟空", "鳴人", "魯夫", "流川楓", "芙莉蓮"]
>>> len(heroes)
5
雖然 len() 函數字面上的意思是「長度(length)」,但它算出來的結果就是這個陣列有幾顆元素。事實上,不只是串列,在 Python 只要是可以一個一個把東西拿出來的東西,都能使用 len() 函數取得個數,例如前面介紹過的字串,以及後面章節會介紹的字典、Tuple 跟集合也都能用。
索引值
接下來,如果想要取出串列裡的某一個元素,使用中括號搭配「索引值(Index)」就能取得指定元素。在 Python 的串列索引值是從 0 開始算,例如我想要印出「悟空」的話,它在這個 heroes 裡是第一顆元素,它的索引值就是 0。同理,在串列裡「魯夫」是第三顆元素,它的索引值就是 2。我們可以把它們印出來試試看:
>>> heroes = ["悟空", "鳴人", "魯夫", "流川楓", "芙莉蓮"]
>>> heroes[0]
'悟空'
>>> heroes[2]
'魯夫'
如果想要印出最後一個「芙莉蓮」的話呢?因為它是最後一個,掐指一算就會知道它的索引值是 4,所以使用 heroes[4] 就行了。這樣寫是沒問題,但如果遇到串列比較長一點的,算起來就有點麻煩。在 Python 有更簡單的寫法,就是使用負的索引值。負的索引值可以從後面算回來,例如 -1 就會取得這個串列的最後一顆元素,同理可證,索引值 -2 就會取得「流川楓」:
>>> heroes[-1]
'芙莉蓮'
>>> heroes[-2]
'流川楓'
那如果使用超過範圍的索引值呢?像這樣:
print(heroes[1450]) # 會印出什麼?
很明顯這裡並沒有這麼多元素,所以執行之後就得到 IndexError 錯誤訊息,跟你抱怨你給的索引值超過範圍了:
IndexError: list index out of range
使用索引值不只可以從串列裡取得元素,也可以把指定位置的元素換掉:
>>> heroes = ["悟空", "鳴人", "魯夫", "流川楓", "芙莉蓮"]
>>> heroes[0] = "JoJo"
>>> heroes[-1] = "DIO"
>>> heroes
['JoJo', '鳴人', '魯夫', '流川楓', 'DIO']
上面這段程式碼意思,就是分別把第一個元素「悟空」換成「JoJo」,並且把最後一個元素「芙莉蓮」換成「DIO」。
巢狀串列
所謂的巢狀串列(Nested List)就是指串列裡又�包了其他的串列,大概就是大腸包小腸的概念,看起來可能會像這樣:
heroes = [["悟空", "達爾"], ["鳴人", "佐助"], ["櫻木花道", "流川楓"]]
為什麼要在串列裡又包串列搞這麼複雜?通常是因為想把一些相關的資料放在一起,使用巢狀串列就會相對的更簡單、更有組織性一點。要取得巢狀串列裡的元素,也是透過索引值的方式,只是要再多一層 []。例如我想印出在第 2 個元素裡的第 1 個元素「鳴人」:
>>> heroes[1][0]
'鳴人'
如果想要把整個巢狀串列裡的元素都印出來的話,用兩層迴圈就能做到:
heroes = [["悟空", "達爾"], ["鳴人", "佐助"], ["櫻木花道", "流川楓"]]
for hero in heroes:
for character in hero:
print(character)
這樣就搞定了。
《冷知識》為什麼索引值從 0 開始?
有沒有想過為什麼我們從小學習的數學是從 1 開始算,但好像大部份比較主流的程式語言的陣列包括 Python 的串列,索引值卻是從 0 開始算?因為這是因為陣列的索引值並不是指向元素本身,比較像是記憶體位置的「偏移量」。假設有一個陣列像這樣:
chars = ['a', 'b', 'c', 'd']
當我們說「變數 chars 指向 ['a', 'b', 'c', 'd']」的時候,並不是 chars 這個變數直接指向這一整個陣列,而是指向這個陣列的「起始位置」,更精準的說是記憶體位置。陣列在記憶體裡的位置跟門牌號碼一樣都是連號的,假設這個陣列的起始記憶體位置是 1450,然後每個元素所佔的位置或說格子的大小我先隨便假設是 8(先不用管它的單位以及為什麼是 8)。大概示意圖如下:
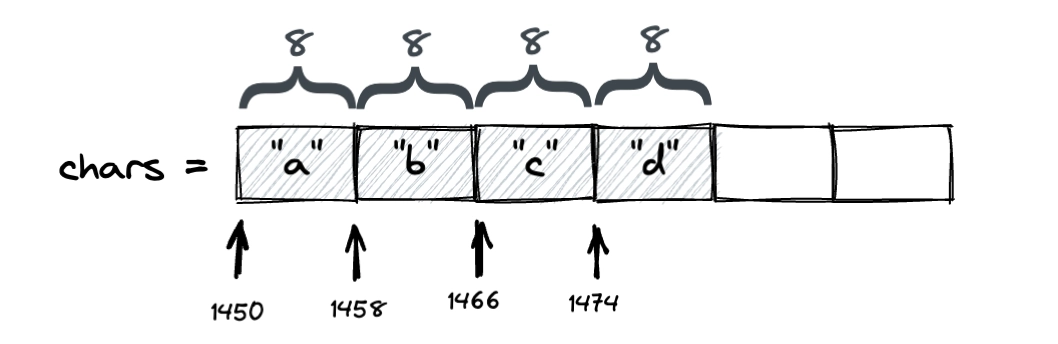
這樣的話,你認為要如何取得第一個元素的 a 字元?不就是指向記憶體位置 1450 就拿到了嗎?如果知道怎麼拿第一個元素,要怎麼拿第二個、第三個元素?這簡單,因為每個格子的寬度是固定的,所以只要知道第一個元素的位置再搭配簡單的加法跟乘法就能算出來了:
第 2 個元素 = 1450 + (1 x 8) = 1458
第 3 個元素 = 1450 + (2 x 8) = 1466
依此類推,所以我們就能推導出第 N 個元素的計算公式:
第 N 個元素 = 起始位置 + ((N - 1) x 8)
到這裡,大家可能也有發現上面公式裡的 N - 1,剛好就是我們平常在講的索引值。所以索引值其實就是記憶體位置的「偏移量」,因此才會從 0 開始。
陣列索引值從 0 開始算的概念是從滿早期的程式語言開始就有了,大家用著用著也習慣了,Python 以及其他程式語言也都受到影響,所以 Python 的串列索引值也跟著從 0 開始算。
但並不是所有程式語言的索引值都是從 0 開始算,不同程式語言對這件事有不同的觀點,像程式語言 Lua、Fortran、COBOL、Julia 跟 R 語言等都是從 1 開始算的,也許在它們的觀點來看,chars[1] 就是第一個字或第一個欄位,看起來更簡單、直覺。
元素是否存在?
要如何知道某個元素是不是有在這個串列裡呢?有幾種做法,比較簡單又直覺的寫法�,就是使用 in 關鍵字:
>>> heroes = ["五條悟", "悟空", "鳴人", "三井壽"]
>>> "悟空" in heroes
True
>>> "芙莉蓮" in heroes
False
不管這個元素是否存在串列中,in 關鍵字一定會給一個布林值的答案,不會無聲卡。這很常在進行邏輯判斷的時候用到,例如:
heroes = ["五條悟", "悟空", "鳴人", "三井壽"]
if "悟空" in heroes:
print("悟空在家")
else:
print("哥哥不在家,今天不賣酒!")
有沒有發現這語法還滿直覺的?就算你不會寫程式,只要略懂英文就大概能猜的出意思,這也是 Python 這個程式語言的優點之一。除了 in 關鍵字之外,還可以透過串列本身提供的 .index() 方法來取得某個元素在這個串列裡的索引值:
>>> heroes = ["五條悟", "悟空", "鳴人", "三井壽"]
>>> heroes.index("悟空")
1
"悟空" 在第 2 個位置,所以會得到索引值 1。不過要注意如果試著問它某個不存在的元素的話,像這樣:
>>> heroes.index("芙莉蓮")
如果 "芙莉蓮" 不在 heroes 串列裡,在其他程式語言可能不會出錯而是得到 -1 或是 undefined 之類的答案,表示不在隊伍裡。但 Python 會給你一個 ValueError 的錯誤訊息,很明確的告訴你這裡沒有這個人:
ValueError: '芙莉蓮' is not in list
另外還有一個方法是使用串列的 .count() 方法,這個方法會回傳某個元素在串列裡出現的次數,如果完全沒有出現的話會得到 0:
>>> heroes = ["五條悟", "鳴人", "鳴人", "鳴人", "鳴人", "鳴人", "三井壽"]
>>> heroes.count("鳴人")
5
>>> heroes.count("魯夫")
0
在上面這幾個方法,雖然我們使用串列的 .index() 或 .count() 方法來得��知某個元素是否存在串列裡,但如果只是要判斷有或沒有的話,使用 in 關鍵字得到布林值會更適合而且更不容易出錯,看看底下這個例子,想想看答案是什麼:
heroes = ["五條悟", "悟空", "鳴人", "三井壽"]
if heroes.index("五條悟"):
print("找到了")
else:
print("沒找到")
乍看之下,你可能會以為會印出 找到了,但答案卻剛好相反。這是因為 .index() 方法會得到索引值 0,在前面布林值章節曾經介紹過數字 0 在 Python 裡會被判定成 False,所以反而會印出 沒找到,這結果可能不是你想要的。
印出所有元素
如果想把串列裡的所有元素都印出來,可以使用上個章節學到的 for 迴圈:
heroes = ["五條悟", "悟空", "鳴人", "三井壽"]
for hero in heroes:
print(hero)
這裡我會使用 hero 當做迴圈裡的變數名稱,而不是隨便用個 a 或 i 這種沒什麼相對比較沒有意義的名字。變數叫什麼名字對 Python 來說並沒有差別,也沒有強制規定,反正執行之後的結果都一樣。但我希望在迴圈裡的變數名稱可以看起來知道自己在做什麼,所以我遇到這種一整群的資料通常會用複數型態方式來命名,個別的變數則會使用單數型態,這樣程式碼的可讀性會好一些。如果用 while 迴圈也沒問題,只是得額外加個變數:
heroes = ["五條悟", "悟空", "鳴人", "三井壽"]
i = 0
while i < len(heroes):
print(heroes[i])
i += 1
看起來還是 for 迴圈比較簡單一點。
新增元素
串列有一些不錯用的方法,可以讓原有的串列加入新的元素,例如 .append() 方法可以把新的元素加到串列的最後面:
>>> heroes = ["悟空", "鳴人", "芙莉蓮"]
>>> heroes.append("娜美")
>>> heroes
['悟空', '鳴人', '芙莉蓮', '娜美']
這樣就可以把 "娜美" 加到 heroes 串列的最後面了。.append() 方法一次只能新增一個元素,如果想一口氣加入多個元素,可以使用 .extend() 方法來幫串列進行「擴充」:
>>> heroes = ["悟空", "鳴人", "芙莉蓮"]
>>> heroes.extend(["娜美", "魯夫", "索隆"]) # 一次加入 3 個
>>> heroes
['悟空', '鳴人', '芙莉蓮', '娜美', '魯夫', '索隆']
如果是要把元素從串列前面加進來的話,則是使用 .insert() 方法搭配索引值就能新的元素安插到指定的位置上,例如:
>>> heroes = ["悟空", "鳴人", "芙莉蓮"]
>>> heroes.insert(1, "魯夫")
>>> heroes
['悟空', '魯夫', '鳴人', '芙莉蓮']
.insert(1, "魯夫") 的意思是指要在索引值 1,也就是這個串列第 2 格的位置,安插元素 "魯夫"。如果有看懂 .insert() 的用法的話,把索引值設定成 0 就等同於在最前面加入新元素,而把索引值設定成 len(heroes) 就等於是在最後面加入新元素,例如:
>>> heroes = ["悟空", "鳴人", "芙莉蓮"]
>>> heroes.insert(0, "五條悟")
>>> heroes
['五條悟', '悟空', '鳴人', '芙莉蓮']
移除元素
如果你對某個元素不滿意,想把它刪掉有好幾種做法,首先可使用串列的 .pop() 方法並搭配索引值就能把指定的元素拿出來:
>>> heroes = ["五條悟", "悟空", "鳴人", "芙莉蓮", "三井壽"]
# 拿掉最後一個元素
>>> heroes.pop()
'三井壽'
>>> heroes
['五條悟', '悟空', '鳴人', '芙莉蓮']
# 拿掉第一個元素
>>> heroes.pop(0)
'五條悟'
>>> heroes
['悟空', '鳴人', '芙莉蓮']
# 拿掉第二個元素
>>> heroes.pop(1)
'鳴人'
>>> heroes
['悟空', '芙莉蓮']
.pop() 方法如果沒有給索引值的話,會把串最的最後一個元素拿出來,如果有給索引值的話,則會取出索引值所指的元素。但萬一串列裡已經沒東西的話:
heroes = []
heroes.pop() # 這裡會...?
已經沒有東西可以拿啦!這時候 Python 會給你一個 IndexError 錯誤訊息,並且告訴你這個串列已經是空的了:
IndexError: pop from empty list
要刪除串列裡的元素,另一個做法是使用 .remove() 方法:
>>> heroes = ["五條悟", "悟空", "悟空", "鳴人", "三井壽"]
>>> heroes.remove("鳴人")
>>> heroes
['五條悟', '悟空', '悟空', '三井壽']
.remove() 方法可以帶入某個元素,如果在這個串列裡有出現的話就會把它移掉。不過需要注意的是,如果這個串列裡有兩個同樣的元素的時候,.remove() 方法只會拿掉第一個,剩下的會留著;
>>> heroes = ["五條悟", "悟空", "悟空", "鳴人", "三井壽"]
>>> heroes.remove("悟空")
>>> heroes
['五條悟', '悟空', '鳴人', '三井壽']
如果想要把所有的 "悟空" 都移掉的話,可以用我們在上個章節學到的迴圈:
heroes = ["五條悟", "悟空", "悟空", "鳴人", "三井壽"]
while "悟空" in heroes:
heroes.remove("悟空")
print(heroes) # 印出 ['五條悟', '鳴人', '三井壽']
像這樣跑個 while 迴圈就行了。另外也可以使用 Python 的串列特有的「串列推導式(List Comprehension)」來做到一樣的效果,而且寫起來更簡潔,這個我們後面一點的章節再來介紹。
相對的,使用 .remove() 方法的時候,萬一在這個串列裡完全沒有符合的元素的話:
heroes = ["五條悟", "悟空", "鳴人", "三井壽"]
heroes.remove("櫻木花道") # 這會...?
"櫻木花道" 不存在原本的 heroes 串列裡,跟前面介紹到的 .index() 方法一樣,Python 會給你一個 ValueError 的錯誤訊息,明確的跟你說這裡沒有這傢伙:
ValueError: list.remove(x): x not in list
假設如果整個串列裡的元素全部都不要了,可使用串列的 .clear() 方法:
>>> heroes = ["悟空", "鳴人", "芙莉蓮"]
>>> heroes.clear()
>>> heroes
[]
就能全部都清掉了。
排序、反轉、合併
串列裡的元素可以使用串列 .sort() 方法來進行排序,這個方法的名字也相當直覺:
>>> numbers = [9, 5, 2, 7, 4, 3, 8, 1]
>>> numbers.sort()
>>> numbers
[1, 2, 3, 4, 5, 7, 8, 9]
你可能覺得這樣的結果看起來很理所當然,但要注意串列的 .sort() 方法會直接改變原本的串列。我不確定這是不是你想要的結果,如果你只是想要得到排序的結果但並不想改原本的串列的話,應該使用 Python 的內建函數 sorted():
>>> numbers = [9, 5, 2, 7, 4, 3, 8, 1]
>>> sorted_numbers = sorted(numbers)
>>> sorted_numbers
[1, 2, 3, 4, 5, 7, 8, 9]
>>> numbers
[9, 5, 2, 7, 4, 3, 8, 1]
注意,是 sorted() 函數,不是串列本身自帶的 .sort() 方法喔。這個方法很好用,只要是可以迭代的物件,都可以交給 sorted() 函數進行排序。
不管是串列本身的 .sort() 方法,還是內建函數 sorted(),你有想過��是依照什麼規則來排序嗎?數字的話可能還容易猜,如果是字串呢?例如:
>>> heroes = ["Batman", "Superman", "Hulk", "Ironman", "Captain America"]
>>> sorted(heroes) # 會印出什麼?
如果是要幫字串做排序的話,Python 會依照字串的第一個字元來排序,如果第一個字都一樣的話,就比第二個、第三個字元,直到比出輸贏為止。以上面這個例子來說,B 開頭的 "Batman" 會排在最前面,而 H 開頭的 "Hulk" 會排最後面。但如果想要照其他規則來排呢?我們可以指定排序的方式,也就是指定 key 參數,例如我想按照名字的「字數」來排,字母越少的排越前面:
>>> heroes = ["Batman", "Superman", "Hulk", "Ironman", "Captain America"]
>>> sorted(heroes, key=len)
['Hulk', 'Batman', 'Ironman', 'Superman', 'Captain America']
這裡 key=len 的意思是指定排序的規則是用內建的 len() 函數來計算字串的長度,算出來的數字越小的排越前面,這樣一來 4 個字的 "Hulk" 會排在最前面,而 "Captain America" 的字數最多所以會排在最後面。不管是內建的 sorted() 函數或是串列自帶的 .sort() 方法都可以指定 key 參數來決定排序的方法。不只內建的函數可以,自己寫的函數也可以,例如我希望排序的方式是「名字裡面有 man」的角色排前面:
def name_with_man(name):
if "man" in name.lower():
return 0
return 1
heroes = ["Batman", "Superman", "Hulk", "Ironman", "Captain America"]
print(sorted(heroes, key=name_with_man))
這裡我定義了一個叫做 name_with_man() 的函數,如果名字裡有 man 就得到數字 0,否則就是數字 1,這樣最後在排序的時候有 man 的角色算出來的都是 0,排序的時候就會排在前面了。如果函數看不懂在寫什麼沒關係,在後面的章節還有更詳細的介紹,這裡先有個印象就好。
排序不只正向排序,雖然待會我們就會介紹到 .reverse() 方法可以用來反轉串列,但如果能在排序的時候就直接反向排序的話不是更簡單嗎?sorted() 函數跟 .sort() 方法都有一個 reverse 參數,它的預設值是 False,也就是預設就是正向排序,如果把這個參數設定成 True 的話就會變成反向排序:
>>> numbers = [9, 5, 2, 7, 4, 3, 8, 1]
>>> numbers.sort(reverse=True) # 反向排序
>>> numbers
[9, 8, 7, 5, 4, 3, 2, 1]
如果只是要反轉的話,使用串列自帶的 .reverse() 方法也能做到這件事:
>>> numbers = [9, 5, 2, 7]
>>> numbers.reverse() # 反轉!
>>> numbers
[7, 2, 5, 9]
同樣要注意的是,.reverse() 方法跟 .sort() 方法一樣,都會直接改變串列本身。
最後,如果我想把串列裡的每個元素組成一個字串,例如想把 ["悟空", "達爾", "蜘蛛人", "蝙蝠俠"] 變成 悟空x達爾x蜘蛛人x蝙蝠俠,可以怎麼做?先使用 for 迴圈來試看看:
heroes = ["悟空", "達爾", "蜘蛛人", "蝙蝠俠"]
all_heroes = ""
for hero in heroes:
all_heroes += hero + "x"
all_heroes = all_heroes[:-1] # 把最後的 `x` 去掉
print(all_heroes) # 印出 悟空x達爾x蜘蛛人x蝙蝠俠
這寫法感覺有點呆,而且最後還得再手動把最後一個 x 去掉,有點麻煩。我們在數字與字串的章節曾經介紹過的 .join() 方法也能用在這個地方:
>>> heroes = ["悟空", "達爾", "蜘蛛人", "蝙蝠俠"]
>>> "x".join(heroes)
'悟空x達爾x蜘蛛人x蝙蝠俠'
看到這裡,不知道大家有沒有發現不只是 .join() 方法可以用在不同的資料型態上,很多 Python 的方法都能用在不同但有類似設計的資料型態上,例如只要是能一個一個被拿出來的可迭代(Iterable)的物件都可以這樣玩。
可迭代物件
「迭代(Iteration)」的意思是指一個一個讀取物件裡面的元素的行為,如果是可以被這樣操作的物件,就可稱它為「可迭代」(Iterable)物件。在 Python 的世界中,前面介紹過的字串,本章介紹的串列、待會就會提到的陣列,以及在後面章節會講到的元組(Tuple)、字典以及集合等等都是可迭代物件。不只這些內建的資料型態,就算是自己寫的物件只要符合某些規格就可以被視為可迭代物件,這就等後面介紹到「物件導向程式設計(OOP)」的時候再來說明。
Python 有內建一些專門用來處理可迭代物件的函數,而且還挺方便的,例如計算串列的總和 sum() 函數:
# 一般的數字串列
>>> sum([1, 4, 5, 0])
10
# 整數、浮點數混合有布林值的串列
>>> sum([2, True, 3.1, False])
6.1
只要串列裡元素都是數字或是布林值(布林值在 Python 裡面就是 0 跟 1),它就可以幫你做加總。但如果裡面有混了不是數字類型的元素,就會出現錯誤:
>>> sum(["1", 2, 3])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'
還有不久前才看到的 sorted() 函數可以用來排序:
# 對數字串列排序
>>> sorted([1, 4, 5, 0])
[0, 1, 4, 5]
# 對字串串列排序
>>> sorted(['z', 'y', 'x'])
['x', 'y', 'z']
# 字串也能排序
>>> sorted('hello')
['e', 'h', 'l', 'l', 'o']
另外,還有可以判斷可迭代物件裡面有沒有任何一個元素是 True 的函數 any(),以及判斷是不是都是 True 的函數 all():
>>> any([False, False, False])
False
# 只要有一個是 True 就行了
>>> any([True, False, True])
True
# 所有的元素都要成立
>>> all([True, True, True])
True
# 只要有一個不成立就不行!
>>> all([True, False, True])
False
在上個章節介紹過的 enumerate 也可用在可迭代物件上,它會把可迭代物件裡的元素一個一個拿出來,加上索引值再包成 Tuple 串列:
# 可以對串列這樣做
>>> heroes = ["悟空", "達爾", "蜘蛛人", "蝙蝠俠"]
>>> list(enumerate(heroes))
[(0, '悟空'), (1, '達爾'), (2, '蜘蛛人'), (3, '蝙蝠俠')]
# 字串也可以
>>> message = "hello"
>>> list(enumerate(message))
[(0, 'h'), (1, 'e'), (2, 'l'), (3, 'l'), (4, 'o')]
大家如�果有機會查看 Python 官方文件的話,會發現很多可以用來處理可迭代物件的函數,只要參數是可迭代物件,不管是字串、串列、Tuple、字典、集合,甚至是自己寫的物件都可以丟進去玩看看。
同一個串列?
先來看看以下這個寫法:
>>> a = [1, 2, 3]
>>> b = a
>>> a
[1, 2, 3]
>>> b
[1, 2, 3]
這程式碼看起來應該還滿直覺的,看起來像是先建立串列 [1, 2, 3] 指定給變數 a,然後讓變數 b 也指定成變數 a,所以這時候變數 a 跟 b 都是串列 [1, 2, 3]。嗯...這樣的講法我不能說你錯,只是不夠精準。
前面曾經有提過,在很多程式語言裡,一個等號不是「等於」的意思,而是「指定」的意思。指定不就是等於嗎?不完全是。當我們說 a = [1, 2, 3] 的時候,我們是在說變數 a 指向串列 [1, 2, 3],而不是說變數 a 等於串列 [1, 2, 3]。同理,b = a 的意思是變數 b 指向變數 a 所指向的地方,也就是指向串列 [1, 2, 3]。所以,你可以把 b = a 的結果看成以下這張圖:

你可能會好奇,就算是這樣又有什麼問題嗎?因為現在 a 跟 b 都指向同一個串列,所以如果我們透過其中任何一個變數修改串列的時候,另一個變數的值也會跟著變:
>>> a = [1, 2, 3]
>>> b = a
# 這時候 a 跟 b 是指向同一個串列
>>> a is b
True
# 試著改變串列 a 的第一個元素
>>> a[0] = 100
# 串列 a 的值改變了
>>> a
[100, 2, 3]
# 但串列 b 的值也跟著改變了
>>> b
[100, 2, 3]
因為 b = a 的意思就是「把變數 b 指向跟變數 a 同一個地方」的意思。
這是不是你想要的結果?我不確定,但如果不是,你想要這兩個串列看起來一樣,但又想要這兩個串列彼此不互相影響,應該就要使用「複製」的手法。在 Python 有幾種方式可以複製串列,比較直覺的方式就是使用串列的 .copy() 方法:
>>> a = [1, 2, 3]
>>> b = a.copy() # 複製
# a 與 b 已經是不同的東西
>>> a is b
False
# 修改串列 a 的第一個元素
>>> a[0] = 100
>>> a
[100, 2, 3]
# 串列 b 還是沒變
>>> b
[1, 2, 3]
需要特別注意的是 .copy() 方法只會複製第一層的元素,如果串列裡面還有串列,也就是巢狀串列,內層的串列還是指向同一個串列喔。如果想要複製這種比較有深度的串列,可使用 copy 模組裡的 deepcopy() 函數:
import copy
heroes = [["悟空", "達爾"], ["鳴人", "佐助"], ["櫻木花道", "流川楓"]]
cloned_heroes = copy.deepcopy(heroes)
另一個做法就是使用 list() 函數:
>>> a = [1, 2, 3]
>>> b = list(a) # 依照串列 a 的內容建立一個新的串列 b
# a 跟 b 的內容是一樣的,但 a 與 b 已經是不同的東西
>>> a == b
True
>>> a is b
False
# 修改串列 a 的第一個元素
>>> a[0] = 100
>>> a
[100, 2, 3]
# 串列 b 還是沒變
>>> b
[1, 2, 3]
喔,還有一種方式也可以做到複製串列的效果,就是接下來要介紹的好用功能,切切切切..切片!
切片(Slice)
在前面章節介紹字串的時候曾經介紹過字串的「切片」,Python 的切片操作基本上可以在任何可迭代物件上使用,除了字串,包括串列以及後面章節才會介紹到的字典、Tuple 以及集合(Set)都可以切,而且切起來的手感幾乎一模一樣,可以讓我們從現有的東西身上切一段東西出來用。
因為操作起來跟字串的切片幾乎一樣,所以就不再詳細介紹一次,這裡主要介紹一些跟字串切片不太一樣的地方。串列跟字串最大的差別,就是字串是不可變的,也就是不能改變字串裡的某個字。但串列是可以變的,可以透過一些�操作換掉串列裡面的元素。舉個例子:
>>> chars = ["a", "b", "c", "d", "e"]
>>> chars[0:2]
['a', 'b']
# 把 chars[0:2] 的元素替換成 [1, 2, 3]
>>> chars[0:2] = [1, 2, 3]
>>> chars
[1, 2, 3, 'c', 'd', 'e']
# 把 c, d, e 元素換成 4, 5
>>> chars[3:6] = [4, 5]
>>> chars
[1, 2, 3, 4, 5]
這裡我把 chars[0:2] 的元素被替換成了 [1, 2, 3],順便也把剩下的 ["c", "d"] 也換成了 [4, 5]。串列可以這樣做,但字串不行,因為字串是不可變,所以像這樣的切片操作在字串上是會出錯的。同理,這樣的切片操作也沒問題:
>>> numbers = [1, 2, 3, 4, 5]
>>> numbers[::2] = [0, 0, 0] # 把索引是奇數的元素替換成 0
>>> numbers
[0, 2, 0, 4, 0]
切片的第三個參數是移動距離(Step),所以在上面的範例中,numbers[::2] 指的就是 [1, 3, 5],然後把這些元素替換成 [0, 0, 0]。
串列推導式
串列推導式(List Comprehension)是 Python 裡一個很有趣的設計,也算是 Python 的特色之一,雖然維基百科上是叫它這個名字,但我對原文的「Comprehension」一直找不到合適的中文翻譯,有些會翻譯成「解析」,但就算翻譯了,也不太容易理解它到底是在做什麼,本書就暫且�讓我用「推導式」來稱呼它。
所以,推導式是什麼呢?推導式是一個把一堆資料經過處理之後產生出另一堆新資料的過程,更白話一點,推導式就是在做「資料轉換(Transform)」,正因為推導式是資料轉換,所以它不會無中生有。原本如果要做到類似的事可能得寫個迴圈,但透過推導式我們可以用簡短的語法就能得到我們想要的資料。在 Python 裡,串列、字典、Tuple、集合都有推導式的寫法,用法也大同小異,這裡我們先來看看串列推導式。
前面有學過如何透過 range 快速的建立串列,如果遇到想要產生比較複雜的串列,通常就是寫個迴圈,在迴圈裡面加入判斷,然後把符合條件的資料丟進串列裡。串列推導式的目的,是讓我們可以用一行程式碼就能快速建立我們想要的串列。不過,在往下介紹之前,我想先問問大家有沒有在數學課學過「集合表示法」?它可能看起來像這樣:
數字集合1 = { x | x > 0 且 x < 10 且 x 為偶數 }
數字集合2 = { 2n | n 為 1 ~ 4 的自然數 }
以前在高中的數學課有學過這樣的寫法嗎?是忘記了,還是害怕想起來?不管如何,上面這兩種表示法都能得到一個從 0 到 10 之間的偶數集合 {2, 4, 6, 8}。Python 的串列推導式跟集合表示法有點像,只是改用 for .. in .. 再適當的搭配 if 判斷。串列推導式的基本款語法格式大概是這樣:
[ 結果 for 個體 in 集合 ]
先來個簡單的:
>>> numbers = [num for num in range(5)]
>>> numbers
[0, 1, 2, 3, 4]
串列推導式最終會產出一個串列,所以在語法的外層有個 [] 包起來。在這個範例中的 num 是一個變數,變數名字你可以自己決定,它是在後面的 for 迴圈裡面定義的。以結果來說,會把 range(5) 產生的數字一個一個的給 num 變數,然後把 num 收集成一個新的串列。上面的寫法跟下面的程式碼是等價的:
numbers = []
for num in range(5):
numbers.append(num)
print(numbers) # 印出 [0, 1, 2, 3, 4]
如果只是要產生 [0, 1, 2, 3, 4] 這種簡單的串列,我直接 list(range(5)) 就結束了,不需要這樣大費周章。但是如果想要建立一個「有規則」的串列,用串列推導式的寫法就會簡單很多,例如我想建立一個從 1 到 9 的數學的平方數串列,可以這樣寫:
>>> [num * num for num in range(1, 10)]
[1, 4, 9, 16, 25, 36, 49, 64, 81]
在 for 前面可以做一些額外的計算,最後計算的結果會被收集成一個新的串列。如果想要建立一個有 10 個 0 的串列呢?用 for 迴圈不難寫,但用推導式寫起來會更簡單:
>>> [0 for _ in range(10)]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
不過如果要做這件事,我們在字串章節學過的 * 運算子可能會更簡單:
>>> [0] * 10
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
這樣就能快速建立一個有 10 個 0 的串列。不過這裡有個坑要小心,就是萬一串列裡的元素是可變的物件,例如串列、字典或集合,用 * 建立的串列裡的元素都會是同一個物件:
>>> empty_lists = [[]] * 3
>>> empty_lists
[[], [], []]
# 對第一個空串列加入元素 123
>>> empty_lists[0].append(123)
>>> empty_lists
[[123], [123], [123]]
因為它們都是同一顆物件,所以對任何一個串列做修改都等同於對其他串列做修改。用串列推導式來建立的話就沒這問題:
empty_lists = [[] for _ in range(3)]
裡面的元素就都會是不同的空串列了。
類似的例子還有:
>>> a = [[1, 2, 3]]
>>> double_a = a + a
>>> double_a
[[1, 2, 3], [1, 2, 3]]
串列之間的 + 可以把兩個串列組合在一起,這看起來沒什麼問題,但事實上 double_a 裡面的兩個串列是同一顆物件,所以對其中一個串列裡的元素做修改,另一個串列也會跟著變:
>>> double_a[0][0] = "x"
>>> double_a
[['x', 2, 3], ['x', 2, 3]]
所以,下回遇到串列裡有其他可變物件的時候,操作的時候要特別小心。
串列推導式不是只能做數學運算,你想的到的操作都能做,例如:
# 把每個字元轉成大寫
>>> [char.upper() for char in "hello"]
['H', 'E', 'L', 'L', 'O']
# 對每個數字做四捨五入
>>> science_numbers = [3.14, 9.81, 2.718]
>>> rounded_numbers = [round(num) for num in science_numbers]
>>> rounded_numbers
[3, 10, 3]
條件判斷
在串列推導式裡可以加入條件判斷,就能只處理需要處理的元素,例如我想建立一個從 1 到 10 的偶數串列,可以這樣寫:
>>> [num for num in range(1, 11) if num % 2 == 0]
[2, 4, 6, 8, 10]
看到這裡,不知道是否還記得前面我們剛剛提過的數學集合表示法嗎?我們可以試著用串列推導式來改寫:
# 數字集合1 = { x | x > 0 且 x < 10 且 x 為偶數 }
>>> [n for n in range(1, 10) if n % 2 == 0]
[2, 4, 6, 8]
# 數字集合2 = { 2n | n 為 1 ~ 4 的自然數 }
>>> [2 * n for n in range(1, 5)]
[2, 4, 6, 8]
所以如果把條件判斷也加上去的話,推導式的完整型態會是:
[ 結果 for 個體 in 集合 if 條件判斷 ]
多層串列推導式?
for 迴圈寫一層不夠可以寫兩層,串列推導式也可以寫出多個層次,我就用之前在迴圈章節的練習《九九乘法表》為例:
# 九九乘法表
for i in range(1, 10):
for j in range(1, 10):
print(f"{i} x {j} = {i * j}")
改用串列推導式來寫的話:
multiplication_table = [f"{i} x {j} = {i * j}" for j in range(1, 10) for i in range(1, 10)]
print("\n".join(multiplication_table))
程式碼的確是只有一行,但這一行看起來有點複雜,以程式碼可讀性的角度來看,對我來說這樣的寫法並沒有比較清楚易懂。所以如果串列推導式可能會寫得太複雜的話,倒不如用一般的 for 迴圈來寫就好。在過去的經驗當中,單層的串列推導式通常寫起來會很開心,第二層開始就會突然變的複雜不少,第三層... 嗯,沒事不要寫第三層!
串列推導式的應用範圍非常廣,只要想建立有規則的串列,都可以考慮用串列推導式來寫。
迴圈裡的變數...
在上個章節介紹 for 迴圈的時候曾經提過這個範例:
num = "hellokitty"
# ... 中間可能有很多程式碼 ...
for num in range(10):
hey = "hello"
print(num)
print(num) # 印出 9
print(hey) # 印出 hello
在 for 迴圈裡的變數,像是 num 以及 hey,在 for 迴圈結束之後還是能正常存取,我個人認為這是個不太好的設計,還好這個問題在串列推導式不會發生:
>>> [n for n in range(5)]
[0, 1, 2, 3, 4]
>>> n
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'n' is not defined
可以看到在推導式裡宣告的 n 在結束之後是不能取用的。不過在 Python 2 的話就不是這樣了:
# 注意!這是 Python 2
>>> [n for n in range(5)]
[0, 1, 2, 3, 4]
>>> n
4
還好現在應該大家比較少機會使用 Python 2 了。
串列開箱!
什麼是「開箱(Unpacking)」?搬家的時候我們通常會把行李裝箱打包,搬到新家之後再把箱子裡的東西拿出來,這個動作就是開箱。在 Python 有個方便的設計,讓我們可以簡單的把「箱子裡」的東西拿出來。舉個例子,原本要把串列裡的元素拿出來可能會這樣寫:
>>> heroes = ["悟空", "鳴人", "流川楓"]
>>> goku = heroes[0]
>>> naruto = heroes[1]
>>> rukawa = heroes[2]
>>> goku
'悟空'
>>> naruto
'鳴人'
>>> rukawa
'流川楓'
透過索引值把串列裡的元素拿出來然後指定給變數,這樣的寫法沒有問題,但有更簡單的寫法:
>>> heroes = ["悟空", "鳴人", "流川楓"]
>>> goku, naruto, rukawa = heroes
>>> goku
'悟空'
>>> naruto
'鳴人'
>>> rukawa
'流川楓'
上面的寫法可以��把 heroes 串列裡的元素「分配」給三個變數,這樣就可以不需要透過索引值逐個指定變數了。這樣的寫法在 Python 裡面叫做 Sequence Unpacking,如果你想翻譯成中文就叫它「序列開箱」吧。這裡的「序列」不是只有串列,同樣只要是可以被迭代的物件都可以這樣玩,例如:
# 字串開箱
>>> a, b, c, d, e = 'kitty'
>>> print(a, b, c, d, e)
k i t t y
# Tuple 開箱
>>> x, y = (25.04, 121.51)
>>> print(x, y)
25.04 121.51
這種手法,在其他程式語言也有類似的設計,在 JavaScript 的話是被稱做「解構(Destructuring)」。不過不同的是,如果在開箱的過程中數量搭不起來的話,在 Python 是會出錯的,例如:
>>> heroes = ["悟空", "鳴人", "流川楓"]
# 少一隻不行
>>> goku, naruto = heroes
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)
# 多一隻也不行
>>> goku, naruto, rukawa, someone = heroes
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 4, got 3)
錯誤訊息滿明顯的,這很好,我就喜歡這種有錯直說的設計,有些設計比較隨興程式語言...對,我就是在說 JavaScript,它就不會這麼直白的給錯誤,而是安靜的給個 undefined 就過去了。
如果只想要其中一個,可以用星號 * 來收集剩下的元素:
>>> heroes = ["悟空", "鳴人", "流川楓"]
>>> goku, *others = heroes
>>> goku
悟空
>>> others
['鳴人', '流川楓']
這種 * 的寫法叫做 Extended Unpacking,不管最後收到的元素有幾個,最終的結果都會是一個串列,如果只收到一個元素就自己變成一個串列,如果一個都沒收到,0 個元素也會得到空的串列。
利用這個手法,可以更輕鬆的拿到串列裡的指定的元素,例如我想拿第一個跟最後一個:
>>> characters = ["悟空", "鳴人", "多拉A夢", "流川楓", "佐助", "八神庵"]
>>> head, *_, tail = characters
>>> head
'悟空'
>>> tail
'八神庵'
中間的元素我不需要,不想理它,所以我用了 _ 來當作變數名稱,這樣短短一行就能拿到頭尾元素了。雖然中間用了 * 符號想要吃下所有的元素,但 Python 很聰明知道要留最後一個給 tail,所以中間剩下的元素就都餵給 _ 了。
開箱開一次不夠,可以繼續往下開,例如當我們利用 Python 撰寫爬蟲程式的時候,有時候抓到的資料格式有點雜,例如:
data = ["弗利沙", [10, 20], (1, 23, 530000)]
舉例來說,在這堆資料裡我只想要第一個名字以及第三個元素裡的最後一項戰鬥力,透過序列開箱的寫法,不需要迴圈也不用指定索引值就能做到:
>>> name, *_, (*_, attack_power) = data
>>> name
'弗利沙'
>>> attack_power
530000
這個開箱的手法有那麼一點點 Pattern Matching 的感覺。是說雖然這個語法挺方便的,但要 * 號的寫法是 Python 3.0 之後才有的,如果 Python 版本是 2.x 版的話,會因為不支援而出現語法錯誤。
這些也都是開箱...
事實上,我們在前面講到變數的時候,曾經提過把兩個變數交換值的技巧:
x = 1
y = 2
# 交換 x, y 變數的值
x, y = y, x
等號右手邊的 y, x 這樣的寫法其實是 Tuple 一種省略小括號的寫法:
>>> data = 1, 2
>>> data
(1, 2)
所以 x, y = y, x 之所以會有效果,就是序列開箱的應用。不只這個,在前一章講到 for 迴圈搭配 enumerate() 來產生索引值或流水編號的時候也是利用了這個特性:
heroes = ["悟空", "達爾", "蜘蛛人", "蝙蝠俠"]
for i, hero in enumerate(heroes, 1):
print(f"{i} {hero}")
仔細看一下,有看到 for 後面接的 i, hero 嗎?這也是序列開箱。
開箱運算子
因為 * 可以用在序列開箱,故又稱為開箱運算子(Unpacking Operator)。在前面的例子中我們用 * 來收集剩下的元素,但它還有別的用途,例如可以把 Range 物件的元素給展開:
# 使用 list 來轉換 range 物件
>>> list(range(5))
[0, 1, 2, 3, 4]
# 把 range 物件的元素展開
>>> [*range(5)]
[0, 1, 2, 3, 4]
這樣的寫法可以讓我們更方便的把 range 物件的元素拿出來,就可以不需要再用 list() 來轉換。如果想要把兩個串列合併成同一個,也許可以這麼做:
comic_heroes = ["孫悟空", "魯夫", "宇智波佐助", "琦玉"]
marvel_heroes = ["金剛狼", "鋼鐵人", "奇異博士"]
# 使用加號,這個最簡單、直覺!
all_heroes = comic_heroes + marvel_heroes
# 使用 extend 方法進行擴充,但這個方法會改變原本的串列
comic_heroes.extend(marvel_heroes)
使用開箱運算子,也能做到把兩個串列給展開並放在同一個串列裡:
>>> all_heroes = [*comic_heroes, *marvel_heroes]
>>> all_heroes
['孫悟空', '魯夫', '宇智波佐助', '琦玉', '金剛狼', '鋼鐵人', '奇異博士']
開箱運算子不只能展開串列,只要是可迭代的物件都能做類似的操作,所以遇到不同型別的物件也能組合在一起而不需要另外轉換型態:
# 不同型別的物件
>>> nums = [1, 4, 5, 0]
>>> name = '悟空'
>>> location = (100, 200)
>>> rounds = range(1, 4)
# 指揮艇組合!
>>> values = [*nums, *name, *location, *rounds]
>>> values
[1, 4, 5, 0, '悟', '空', 100, 200, 1, 2, 3]
透過 * 運算子把物件展開再組合滿方便的。開箱運算子還有另一種款式 **,跟一個 * 不同的是,** 是用來開箱字典的,下個章節就會介紹它。此外,如果想把變數展開後傳進函數裡當參數的時候也很方便,但這個細節就留到函數章節再跟大家介紹。
《冷知識》Python 的陣列?
在某些程式語言裡(例如 Rust 跟 C 語言),陣列一開始就得宣告是什麼型態(例如整數陣列或字元陣列),而且裡面只能存放相同型別的元素,用來放數字的,就不能用來放文字。這樣的設計雖然好像比較沒彈性,但換來的是陣列的存取效能很不錯,以下我就用傳統陣列來稱呼它。
傳統陣列宣告之後會跟系統要一塊連續的記憶體來存放資料,因為陣列裡每個元素的型別都是一樣的,表示每個元素所需要的記憶體空間也是一樣大的。大家應該知道陣列是透過索引值來拿取資料,而且現在也知道這一串連續的記憶體的「起點」在哪裡(Start),假設我想要取得這個陣列的第 3 格的資料,我只要提供索引值 2,搭配每一個格子的寬度(Size)再用簡單的數學計算「Start + 2 x Size」,一下子就能找到第 3 格位置的記憶體位置,這也是傳統陣列的存取效能很好的原因。平常大家可能被其他比較高階的程式語言給慣壞了,不會想這麼多細節,反正程式會動就好。
事實上,Python 本身也是有陣列,不過它不是內建的型別,知道的人可能也比較少,甚至有些人認為 Python 的 List 就是陣列。Python 的陣列定義在 array 模組裡面,它跟串列的用法有點像,不過它裡面能裝的東西就沒那麼隨便了,元素必須要是相同的型別:
from array import array
lost_numbers = array("i", [4, 8, 15, 16, 23, 42])
scientific_constants = array("f", [3.14, 9.8, 6.02e23])
spells = array("u", ["臨", "兵", "鬥", "者", "皆", "陣", "列", "在", "前"]) # 這裡也有「陣」跟「列」
在宣告的時候要指定內容物的型別,上面範例裡的 "i" 代表整數、"f" 代表浮點數、"u" 代表 Unicode 字元,也就是說,一開始建立的時候你就已經決定這個陣列裡會放什麼類型的資料了。如果在裡面混入不該出現的東西,像這樣:
numbers = array("i", [1, 2, 3, "有奇怪的東西混進來了"])
執行的時候就會有明確的錯誤訊息:
Traceback (most recent call last):
File "demo.py", line 3, in <module>
numbers = array("i", [1, 2, 3, "有奇怪的東西混進來了"])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: 'str' object cannot be interpreted as an integer
如果你有學過資料結構,也許有聽過「鏈結串列(Linked List)」,鏈結串列正如其名「鏈結」,是由一個一個的節點串在一起,每個節點都有指向下一個節點的指標,這樣的設計讓鏈結串列在處理元素的插入和刪除的時候效率比較好。
當你看到 Python 的串列之所以叫做「串列」而不叫陣列時候,你可能會把它跟 Linked List 聯想在一起,事實上它們內部的設計並不一樣。如果你有機會去翻 Python 的原始碼,你會發現 Python 的串列其實是一個指向物件的動態陣列,這樣的設計可以 Python 的串列可以同時��存放不同型別的資料,同時效能也還不錯。
如果要取用陣列裡的元素,就跟使用串列的方式差不多,也是透過中括號搭配索引值:
>>> from array import array
>>> lost_numbers = array("i", [4, 8, 15, 16, 23, 42])
# 使用索引值
>>> lost_numbers[0]
4
>>> lost_numbers[-1]
42
不過,Python 的陣列跟傳統陣列稍微不一樣的地方,就是 Python 的陣列可以動態增減元素數量:
>>> from array import array
# 正整數陣列
>>> numbers = array("I", [1, 2, 3])
# 在最後面加入數字 100
>>> numbers.append(100)
>>> numbers
array('I', [1, 2, 3, 100])
# 在索引 0 的位置插入數字 10
>>> numbers.insert(0, 10)
>>> numbers
array('I', [10, 1, 2, 3, 100])
雖然可以動態增加元素,但還是不能隨便偷放一些不對的東西進來,例如:
>>> from array import array
# 正整數陣列
>>> numbers = array("I", [1, 2, 3])
>>> numbers.append(-10)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
OverflowError: can't convert negative value to unsigned int
因為 -10 不是正整數,所以會出現錯誤訊息。更多關於陣列介紹以及使用方式可以參考官方文件說明。