元組與集合

元組(Tuple)
在開始之前,先不管 Tuple 是什麼東西或是怎麼翻譯,首先,你覺得 Tuple 該怎麼發音?曾經有人在 Twitter 上問 Python 的發明人 Guido 這個字應該怎麼唸,結果他的回答是:
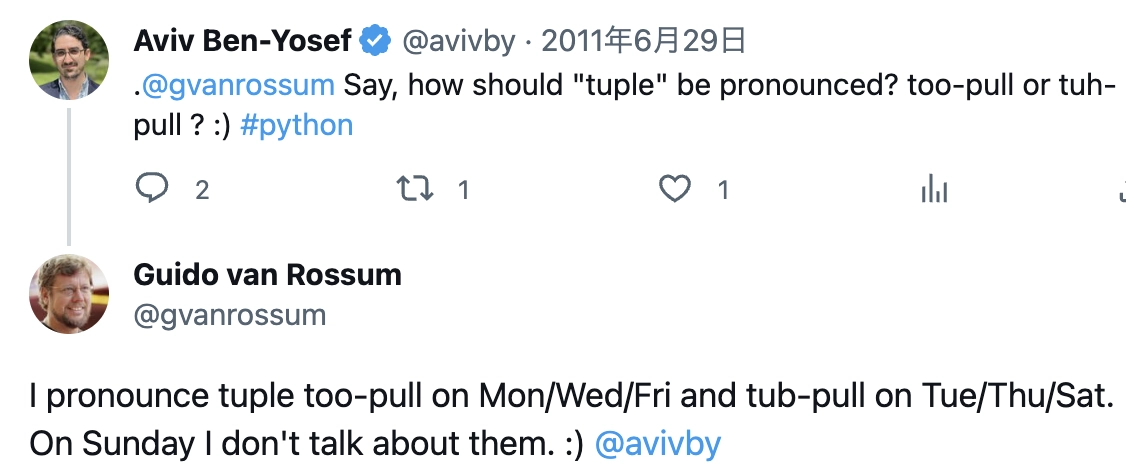
Guido 說他星期一、三、五唸「吐波」,星期二、四、六唸「塔波」,星期日就不唸它。意思就是你想怎麼唸就怎麼唸,只要你自己或你的同事聽的懂就好。至於中文要翻譯成「元組」或「數組」就隨你開心,不過不管哪個翻譯我其實都認為不太容易從字面上理解,所以本書大部份會使用 Tuple 原文。
是說,Tuple 這個字是什麼意思?你可能會查到這個字在數學上代表「有限的有序數列」,但這個字怎麼來的?Tuple 這個字並不是 Python 發明的,這個字的起源跟拉丁文的數字有點關係。我們用英文數東西的時候,一個是 single,兩個是 couple 或 double,三個是 triple,到這裡這幾個字我們可能都還唸的出來,但接下來呢?quadruple、quintuple、sextuple、septuple、octuple、centuple 分別是四、五、六、七、八以及百倍,依此類推。而這些字結尾的 -ple 在拉丁文是 plus 或 more 的意思,所以 n-tuple 就是來自於這些詞的抽象化,而 Tuple 這個名字就是這樣來的。
冷知識講完了,讓我們回來看看 Python 裡的 Tuple。
建立 Tuple
Tuple 跟串列一樣也是一種有順序而且可以裝很多東西的資料結構,只是寫起來的樣子不一樣,使用上也有些不同的地方。雖然看起來跟串列有點像,但真的要比較的話,Tuple 的設計可能跟字串比較接近。在 Python 要建立一個 Tuple,最簡單的方式就是使用小括號 ( ) 把東西包起來,裡面的元素用逗號分開,像這樣:
>>> location = (24.1234, 121.1234)
# 它是個 Tuple
>>> type(location)
<class 'tuple'>
或是可使用 tuple() 把像是串列或字串之類的可迭代物件轉換成 Tuple:
>>> tuple([1, 2, 3])
(1, 2, 3)
>>> tuple('hello')
('h', 'e', 'l', 'l', 'o')
效果一樣,只是寫法不同而已。跟串列一樣,Tuple 裡的資料沒有規定都要相同類型,你想放什麼就放什麼:
>>> medical_record = ('John Doe', 20, '202', True)
跟串列不同的地方除了寫起來的樣子不同之外,最明顯的差異就是 Tuple 是不可變的(Immutable)。這點跟字串的設計是一樣的,也就是說一旦 Tuple 裡的資料設定好之後就不能再改變了,不能新增、修改或移除裡面的元素。
雖然建立 Tuple 的時候並沒有限定元素個數,但如果裡面只打算裝一個元素的話,最後面要加上逗號,不然 Python 會把它當成其他的資料型態:
>>> this_is_not_tuple = ('hello')
>>> type(this_is_not_tuple)
<class 'str'>
# 只有一個的話要加上逗號
>>> only_one = ('hello',)
>>> type(only_one)
<class 'tuple'>
('hello') 其實就是字串,外面的小括號就只是一般的括號而已,只是個裝飾品,有加沒加效果都一樣。所以如果只有一個元素的 Tuple, 別忘了最後要加上逗號。
另外,如果你像我一樣喜歡偷懶,Tuple 的小括號也可以省略不寫,只要把每個元素用逗號隔開,Python 會自動把它當成 Tuple:
>>> numbers = 1450, 9527, 5566
>>> numbers
(1450, 9527, 5566)
>>> type(numbers)
<class 'tuple'>
不過這種寫法有沒有比較容易理解就看個人了,在我的認知裡小括號可以讓我更清楚知道這就是一整包的資料,所以我還是會習慣加上小括號。如果只有一個元素同樣也要加上逗號:
>>> numbers = 9527,
>>> numbers
(9527,)
看起來有點怪,感覺像一句話沒講完。再看看底下這個例子,你猜猜會是什麼結果:
>>> 1, 2 > 1, 3
這到底是兩個 Tuple 在互相比大小,還是一顆三個元素的 Tuple?執從之後會得到 (1, True, 3),這是因為大於小於的優先順序比逗號高,所以 2 > 1 先被計算,這很明顯就不是個應該省略小括號的例子。
看到這裡,Tuple 的小括號可以省略,但逗號卻不行,有沒有一種在 Tuple 的小括號只是配角,逗號才是主角的感覺。
常見操作
Tuple 跟串列一樣是有順序的,所以可透過索引值取得裡面的資料,用起來的手感跟串列一樣,索引值都是從 0 開始算:
>>> medical_record = ('John Doe', 20, '202', 'A')
>>> medical_record[0]
'John Doe'
>>> medical_record[1]
20
>>> medical_record[-1]
'A'
索引值從 0 開始,如果索引值是負的話就是從後面開始算,-1 就是最後一個,-2 就是倒數第二個,依此類推,如果拿超過索引值以外的資料會出現 IndexError 的錯誤,這些操作都跟串列一樣。不過因為 Tuple 是不可變的,所以如果想要改變裡面的元素會發生錯誤:
>>> medical_record = ('John Doe', 20, '202', 'A')
>>> medical_record[0] = 'Mary'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
你也許會想,誰說 Tuple 是不可變的,你看我這樣寫不就改變了嗎:
>>> t1 = (1, 2, 3)
>>> t1 += (4, 5, 6)
>>> t1
(1, 2, 3, 4, 5, 6)
嗯,如果你也這樣認為,那就表示你可能誤解了「不可變」的意思。上面這樣的寫法,其實並不是改變 Tuple ��的內容,而是創建了一個全新的 Tuple,然後把它指定給原本的變數而已。這個行為叫做「重新指定(Reassignment)」,並不是修改 Tuple 的內容。
Tuple 是一種可迭代物件,所以迭代操作也都跟串列一樣,同樣使用 for ... in ... 的方式:
heroes = ("悟空", "鳴人", "魯夫")
for hero in heroes:
print(hero)
然後我們在串列章節介紹過的一些方法,像是內建函數 len() 或是物件身上的 .count() 以及 .index() 之類查詢的方法,Tuple 也都可以使用,這裡就不再贅述。不過因為 Tuple 是不可變動的,所以像是 .append()、.insert()、.remove() 這種會修改 Tuple 的方法就不能用了,使用會出現 AttributeError 的錯誤,就是告訴你 Tuple 沒有這些屬性或方法可以用。
雖說 Tuple 是不可變的,但如果在 Tuple 裡面放的資料是可變的資料型態,例如串列或字典,那麼裡面的串列或字典還是可以修改的,例如:
# 最後一個元素是串列
>>> hero_info = ('悟空', 100, ['克林', '達爾', '比克'])
# 修改最後一個元素裡的第 2 個元素
>>> hero_info[-1][1] = '魯夫'
>>> hero_info
('悟空', 100, ['克林', '魯夫', '比克'])
在上一章介紹到的可雜湊物件,如果 Tuple 裡面所有的元素都是不可變的,我們可以說這個 Tuple 完全是不可變的,它就可以是個可雜湊物件,也可以拿來當字典的 Key;反之如果 Tuple 裡面有可變的資料型態,進行雜湊計算的時候就會被抱怨了。
是說,大家不知道會不會覺得好奇,我們都已經有了串列了,為什麼還需要跟串列操作有七、八成像的 Tuple?Tuple 有什麼特別的地方或是有什麼好處?
先不說別的,光是不可變的資料型態本身就是好處,不過這對於初學者來說可能不太能理解不可變有什麼好處。因為不可變所以不會不小心被誰改到裡面的東西(除非裡面的元素本身是可變動的),這樣資料在各個函數之間被當參數傳來傳去的時候,不用擔心會被哪個函數改到裡面的值。
另外,效能上 Tuple 的效能也比串列好一些,待會就會說明。
複製 Tuple
在前面串列的章節曾經介紹過幾個方式可以用來複製串列:
- 使用
list()函數 - 使用串列物件的
.copy()方法 - 使用
copy模組的copy()函數 - 使用切片
Tuple 物件本身並沒有 .copy() 方法,不過上述其他手法都能用:
import copy
heroes = ("悟空", "鳴人", "魯夫")
clone_heroes1 = tuple(heroes) # 使用 tuple()
clone_heroes2 = copy.copy(heroes) # 使用 copy 模組的 copy() 函數
clone_heroes3 = heroes[:] # 使用切片
看起來沒什麼問題,但上面這些行為跟串列使用 list() 來進行複製是不同的,list() 會真的複製一份串列出來,但因為 Tuple 的設計是不可變的,所以 Python 不會也不需要真的去複製一份新的 Tuple,所以上面這些寫法都是回傳一個指向原本 Tuple 的參考而已:
print(clone_heroes1 is heroes) # True
print(clone_heroes2 is heroes) # True
print(clone_heroes3 is heroes) # True
也就是說,這些複製品根本不是什麼複製品,這跟原本的 Tuple 根本就是同一包東西!
《冷知識》空的 Tuple?
來來來,你猜猜看如果要建立一個空的 Tuple 該怎麼做?不要想太複雜,一個小括號就能搞定:
# 這是空的 Tuple
>>> t1 = ()
>>> type(t1)
<class 'tuple'>
# 用 tuple() 函數也可以
>>> t2 = tuple()
>>> type(t2)
<class 'tuple'>
有趣的是,一般的 Tuple 就算裡面的元素看起一樣,分別建立的 Tuple 就是不同的東西,但如果是空的 Tuple,因為空的就是空的,它跟柯南的真相一樣,只有一個:
# 有料的 Tuple
>>> t1 = (1, 2, 3)
>>> t2 = (1, 2, 3)
>>> t1 == t2
True
>>> t1 is t2
False
# 如果是空的 Tuple
>>> t1 = ()
>>> t2 = ()
>>> t1 == t2
True
>>> t1 is t2
True
Tuple 身為不可變的資料結構,只要建立之後就不能新增或修改,空的 Tuple 當然也不例外。所以,建立一個空的又不能改 Tuple 是有什麼用途?老實說用途不大,但還是有它可以派上用場的地方。舉個例子,像是用在函數的回傳值:
def get_hero(id):
if id == 0:
return ()
else:
# 經過漫長的查詢,終於找到英雄的資訊...
hero_info = ("悟空", 20, "[email protected]")
return hero_info
get_hero() 函數會根據 id 參數查詢資訊,如果 id 是 0 的話就回傳一個空的 Tuple,不然就回傳某位英雄的資料。你可能會好奇為什麼要回傳空的 Tuple,找不到資料的話,難道不能就回傳個 None 或 False 之類的嗎?當然可以,但我希望這個函數的回傳值可以維持一致性,不管找不找的到,回傳的資料型態都是 Tuple,不會因為找不到資料而改變回傳的資料型態,這時候就能使用空的 Tuple 當做找不到資料時候的回傳值。
Tuple 的效能
技術上來說,因為 Tuple 是不可變的,所以它不用像串列一樣需要另外的空間來存放可能會變動的資料,白話的說就是比串列更省記憶體空間,效能上也會比串列好一點點,我們寫一小段程式來做個實驗:
from timeit import timeit
t_list = timeit("heroes = ['悟空', '鳴人', '魯夫']", number=10_000_000)
print("List:", t_list)
t_tuple = timeit("heroes = ('悟空', '鳴人', '魯夫')", number=10_000_000)
print("Tuple:", t_tuple)
timeit 是 Python 內建的模組,可以用來計算執行一段程式碼所需要的時間。這裡我分別只用串列和 Tuple 來做簡單的變數宣告,然後讓它執行一千萬次,看看執行的時間,在我的電腦結果是:
List: 0.31187591701745987
Tuple: 0.056503500032704324
而且 Tuple 在建立的時候佔用的資源也比串列少一點點:
import sys
the_list = list(range(10))
the_tuple = tuple(range(10))
print(sys.getsizeof(the_list)) # 136
print(sys.getsizeof(the_tuple)) # 120
sys 模組裡的 getsizeof() 函數可以用來計算物件佔用的記憶體大小,不同的電腦或作業系統執行的結果可能不太一樣,但 Tuple 佔用的記憶體空間通常都會比串列少一些。
技術上來說,串列跟 Tuple 都是連續的記憶體位置,串列可能會增加新的元素,原本的記憶體空間可能就會不夠放,得再去找更大的連續記憶體空間。如果每加一個元素就得再去找一塊新的連續記憶體空間的話也太辛苦了,所以 Python 在建立串列或是再去要新的記憶體空間的時候,會跟系統多要一點空間裝這些可能會新增的元素,就比較不��用一直找新的位置。而 Tuple 的設計是不可變的,沒有新增元素的問題,所以需要的空間會比串列小一點。
從帳面上來看,Tuple 的效能的確是比串列來的好。Tuple 在寫起來以及用起來的手感都跟串列有點像,所以如果資料是不會變動的,在選擇資料型態的時候不妨先可考慮用 Tuple 來裝東西。
Tuple 推導式?
串列有串列推導式,字典有字典推導式,Tuple 呢?貌似也有類似的東西,但不太一樣...
>>> t1 = (item for item in range(5))
>>> t1
<generator object <genexpr> at 0x10041b280>
基本上就是把串列推導式的中括號 [ ] 改成小括號 ( ) 而已,但大家還記得推導式的用途嗎?推導式就是在做資料轉換,把資料轉換成新的資料。不過不像其他推導式,像上面這樣的寫法並不是產生出一個新的 Tuple,而是得到一個「產生器(Generator)」物件。所以,像上面這樣用小括號寫出來有點像推導式的東西,並不是 Tuple 推導式,而是個「產生器表達式(Generator Expression)」,這寫法會產生一個產生器(有覺得唸起來很繞口嗎)。
我們這裡先不會提到太多關於產生器的細節,在第 11 章的函數進階篇有更多關於產生器詳細介紹,現在你暫時可以把產生器看成一個可迭代物件,所以可以用 for 迴圈把裡面的東西印出來看看:
items = (item for item in range(5))
for i in items:
print(i)
如果想把產生器物件轉換成真正的 Tuple 的話,可使用 tuple() 進行轉換:
>>> t1 = tuple(item for item in range(5))
>>> t1
(0, 1, 2, 3, 4)
因為 Tuple 是使用小括號包起來,所以再加上 for .. in.. 這種類似推導式的寫法,有時候會被認為是 Tuple 推導式,但事實上並不是。但不管你認為它是或不是都沒關係,產生器表達式用到的機會相對比較少一點,而且也沒有串列推導式那麼直覺方便,不過產生器本身的設計倒是挺有趣的,關於產生器的細節會在後面章節再來跟大家介紹。
串列,還是 Tuple?
既然串列跟 Tuple 在操作上感覺很類似,好像差別就在寫法不太一樣以及不可變動而已,那麼該選哪一個呢?這沒有標準答案,我也看過工作很多年的工程師從頭到尾就只用串列也是過得好好的。對我來說,我認為 Tuple 並不只是「不可變的串列」而已,提供一些我的建議供大家參考:
- 第一條也是比較明顯的,如果確定裡面要裝的資料是不會變動的,選 Tuple,有可能需要變動的,選串列。不只因為 Tuple 的效能比串列好一些,同時從資料型態本身也能知道這個容器裡裝的是不會變動的資料,比較不會發生意外。
- 如果是同質性(Homogeneous)的資料,例如都是數字或都是字串,我會選擇串列;異質性(Heterogeneous)的資料,例如裡面有數字、字串、字典等不同型態混著用的,我會選 Tuple。這不是硬性規定,只是我自己個人的習慣,但這點官方文件也有提到:「Tuples are immutable, and usually contain a heterogeneous sequence of elements...」。
集合
講到集合(Set),不知道以前在學校數學課有沒有學過這個東西?沒有也沒關係,我們來 Python 再學一次。在 Python 裡,集合跟串列、Tuple、字典一樣,也是一種資料型態,它跟我們以前在數學課學到的集合很像,而且有一些有趣的特性:
- 集合裡的元素不會重複。
- 集合裡的元素沒有順序,所以取用集合裡的元素的時候不像串列或 Tuple 一樣使用索引值。
建立集合
在 Python 裡,集合的建立方式有兩種,一種是使用大括號 { }:
>>> s1 = {1, 3, 3, 3, 3, 3, 2, 4}
>>> s1
{1, 2, 3, 4}
>>> type(s1)
<class 'set'>
直接用大括號 { } 滿直覺的,因為集合裡的元素不會重複,如果有重複的話會被濾掉。要注意的是,如果是使用大括號 { } 建立集合的話,裡面的元素不能是空的,因為 Python 會把它當成是空字典。所以如果要建立空集合,就要使用 set()。set() 搭配可迭代物件,例如串列、元組、字串都可以:
# 用串列建立集合
>>> s2 = set([1, 3, 3, 3, 3, 3, 2, 4])
>>> s2
{1, 2, 3, 4}
# 用元組建立集合
>>> s3 = set((1, 3, 3, 3, 3, 3, 2, 4))
>>> s3
{1, 2, 3, 4}
# 用字串建立集合
>>> s4 = set('hello')
>>> s4
{'l', 'o', 'e', 'h'}
只要是可迭代物件都可以丟進 set() 來建立集合,不過從上面的字串建立集合的例子可以看到,集合裡的元素是不會重複的,所以即使字串裡有重複的字元,集合裡也只會有一個。所以如果你手上有個重複的串列,你想要把重複的元素刪掉,原本你可能得寫迴圈檢查是否有重複的元素,現在可以利用集合元素不會重複的特性,先把串列丟進 set() 函數裡,再把集合轉回串列:
>>> heroes = ['悟空', '鋼鐵人', '悟空', '魯夫', '蝙蝠俠', '魯夫']
>>> all_heroes = list(set(heroes))
>>> all_heroes
['魯夫', '悟空', '鋼鐵人', '蝙蝠俠']
因為集合沒有順序,所以透過這個過程得到的結果,元素的順序就不一定是我們原本的順序。如果不在乎順序,只是用來計算原本的串列或字串裡總共有幾個不同的元素就挺方便的。
另外,不是所有的元素都可以放進集合裡的,舉個例子,我試著把串列丟進集合裡:
>>> s5 = {[1, 2, 3], 4, 5}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
Python 跟我們抱怨的錯誤訊息應該滿明顯的,元素本身如果不是「可雜湊(hashable)物件」就不能放進集合裡。至於什麼是可雜湊物件可見上個章節的介紹。
還記得我們在前面章節介紹過 nan 的概念嗎?在集合裡也可以放進去:
>>> { 1, 2, 3, float('nan') }
{1, 2, 3, nan}
雖然集合不會有重複的元素,但如果多放幾個 nan 呢?
>>> { 1, 2, 3, float('nan'), float('nan'), float('nan') }
{1, 2, 3, nan, nan, nan}
nan 的特色就是它不會等於任何數值,甚至包括它自己,因此在建立集合的時候,它會認為這裡沒有重複的 nan,所以就會看到好幾個 nan 了。但這種放了好幾個 nan 的集合沒什麼用途,單純就只是好玩而已。
常見操作
首先,集合是一種可迭代物件,所以跟其他可迭代物件一樣使用迴圈來把裡面的元素一個一個拿出來:
heroes = {"悟空", "魯夫", "光之美少女"}
for hero in heroes:
print(hero)
集合裡的元素是沒有順序的,所以在不同的環境執行的結果順序可能會不一樣。也正因為集合沒有順序的原因,其他資料結構如串列、Tuple 或字典的開箱在集合上也可以用,但答案可能不是你想像的那樣:
s1 = {9, 5, 2, 7}
a, *b, c = s1 # 開箱
你把開箱出來的這三個變數印出來就會知道我在講什麼了。如果真的想對集合裡的元素做排序,可搭配 sorted() 函數一起服用。既然集合是一種容器,那有辦法像串列一樣使用索引值或像字典使用 Key 來取得指定的元素嗎?答案是沒有。首先,集合並沒有 Key 可以用,其次,集合裡的元素是沒有順序的,所以也沒有索引值可以使用。事實上,集合這個資料結構也不是讓我們用來取代串列或其他資料結構的,想要做這件事就選擇用串列、字典或 Tuple 吧。
新增元素
不像 Tuple,集合是可以變動的,我們可以對集合做新增、修改或刪除元素。新增元素可使用集合的 .add() 方法:
>>> s1 = {9, 5, 2, 7}
# 新增元素
>>> s1.add('謝謝你')
>>> s1
{'謝謝你', 2, 5, 7, 9}
# 新增重複的元素
>>> s1.add(2)
>>> s1
{'謝謝你', 2, 5, 7, 9}
刪除元素
刪除的話則是使用集合的 .remove() 方法:
>>> s1 = {9, 5, 2, 7}
# 刪除元素 9
>>> s1.remove(9)
>>> s1
{2, 5, 7}
腦筋轉的比較快的你,也許會想到萬一集合裡有好幾個 9,那 .remove(9) 方法會刪除哪一個呢?會刪第一個還是全部符合的都刪掉?這其實是個假議題,你想想看,集合裡面怎麼可能會有好幾個同樣的數字呢?所以根本沒有 .remove() 方法會刪掉哪個元素的問題。但如果要刪除的元素不存在的話,會出現 KeyError 的錯誤:
>>> s1.remove('girl_friend')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'girl_friend'
判斷元素是否存在集合裡,跟判斷有沒有在串列或字串裡的做法一樣,也是使用 in 關鍵字:
>>> 9 in s1
True
>>> 'girl_friend' in s1
False
所以如果擔心在移除元素的時候發生錯誤,可以先用 in 判斷一下再刪。不過也不用這麼麻煩,因為集合還有個跟 .remove() 方法功能類似但比較沒那麼嚴格的方法叫做 .discard(),同樣也是會刪除元素,但如果要刪除的元素不存在的話,就只是靜靜的過去,不會丟出錯誤訊息:
>>> s1.discard('girl_friend')
# 不存在這個元素,但不會出現錯誤
如果要清空集合裡的所有元素,可以使用 .clear() 方法:
>>> s1 = {9, 5, 2, 7}
>>> s1.clear()
>>> s1
set()
就變成乾乾淨淨的空集合了。不過空的集合沒辦法用 { } 來表示,因為這個寫法已經被字典用掉了,所以就只能用 set() 的方式表示目前是個空集合。
複製集合
複製集合的方式跟串列一樣,可以使用 set() 或是集合物件自帶的 .copy() 方法:
>>> all = {1, 2, 3, 4, 5}
>>> s1 = all.copy()
>>> s2 = set(all)
集合因為沒有順序,所以不像串列一樣可以使用切片來複製集合。
集合運算
Python 的集合跟我們以前數學課學的集合一樣,有交集、聯集、差集等運算。在 Python 裡,集合的運算是使用運算子來表示。例如交集(Intersection)使用 & 運算子或是 .intersection() 方法:
>>> s1 = {9, 5, 2, 7}
>>> s2 = {1, 4, 5, 0}
>>> s1 & s2
{5}
>>> s1.intersection(s2)
{5}
交集指的就是兩個集合都有的元素。聯集(Union)是兩個集合的所有元素,在 Python 是使用 | 運算子或 .union() 方法:
>>> s1 = {9, 5, 2, 7}
>>> s2 = {1, 4, 5, 0}
>>> s1 | s2
{0, 1, 2, 4, 5, 7, 9}
>>> s1.union(s2)
{0, 1, 2, 4, 5, 7, 9}
交集跟聯集沒有順序問題,也就是 s1 & s2 跟 s2 & s1 會得到一樣的結果。但差集(Difference)就不一樣了,差集是指只有在第一個集合裡面有,而第二個集合裡面沒有的元素,使用 - 運算子或 .difference() 方法:
>>> s1 = {9, 5, 2, 7}
>>> s2 = {1, 4, 5, 0}
>>> s1 - s2
{9, 2, 7}
>>> s1.difference(s2)
{9, 2, 7}
>>> s2 - s1
{0, 1, 4}
>>> s2.difference(s1)
{0, 1, 4}
集合之間是否有交集,不一定要真的用運算子或方法來算,也可以使用集合的方法來判斷:
>>> s1 = {1, 2, 3}
>>> s2 = {4, 5, 6}
>>> s1.isdisjoint(s2)
True
如果兩個集合完全沒有重疊的元素,.isdisjoint() 方法會回傳 True。
子集合與超集合
集合有大有小�,假設有 s1 跟 s2 兩個集合:
s1 = {1, 2, 3, 4, 5}
s2 = {2, 3, 4}
以上面的例子來說,集合 s2 裡面所有的元素在集合 s1 裡都有,這時候我們就可以說 s2 是 s1 的子集合(Subset),相對的,s1 是 s2 的超集合(Superset)。在數學上常會用 ⊂ 以及 ⊃ 符號來表示:
# s2 是 s1 的子集合
s2 ⊂ s1
# s1 是 s2 的超集合
s1 ⊃ s2
在 Python 如果想要知道某個集合是不是另一個集合的子集合或超集合,可使用集合的 .issubset() 或 .issuperset() 方法:
>>> all = {1, 2, 3, 4, 5, 6}
>>> data1 = {6, 3, 4}
>>> data2 = {1, 4, 5, 0}
# data1 是 all 的子集合
>>> data1.issubset(all)
True
# data2 多了一個 0
>>> data2.issubset(all)
False
集合的 .issubset() 跟 .issuperset() 剛好是兩個相反的方法,可以看情況使用。不過子集合或超集合只講一半,再讓我舉個例子:
all = {1, 2, 3, 4}
s1 = {1, 2, 3}
s2 = {1, 2, 3, 4}
在上面這幾個集合中,集合 s2 剛剛好等於集合 all,但我們還是會說 s1 跟 s2 都是 all 的子集合,不過集合 s1 特別會稱它叫嚴格子集(Proper Subset),在符號上也有一些不同:
# s2 是 all 的子集
s2 ⊆ all
# s1 是 all 的嚴格子集
s1 ⊂ all
嚴格子集的意思就是指就真的只能是集合的一部份,但不能是全部。「嚴格(Proper)」的概念不只在子集合,在超集合也一樣。在 Python 裡面可以使用 < 跟 > 再配合等號 = 運算子來表示子集合或超集合,這個大於小於運算子並不是在比大小:
>>> all = {1, 2, 3, 4}
>>> s1 = {1, 2, 3}
>>> s2 = {1, 2, 3, 4}
# s1 是 all 的嚴格子集
>>> s1 < all
True
# s2 不是 all 的嚴格子集
>>> s2 < all
False
# 但 s2 是 all 的子集合
>>> s2 <= all
True
現在有沒有一種「數學不是一切,但一切都是數學」的感覺呢?
集合推導式
大家都有推導式,集合怎麼可以沒有呢?集合推導式的語法��寫起來跟字典推導式有點接近,都是使用大括號 {}:
>>> s1 = {9, 5, 2, 7}
>>> s_all = { i for i in s1 }
>>> s_all
{9, 2, 5, 7}
推導式大家看到這裡可能有點麻木了,不過接下來我們來看一個平常工作上應該不會發生但我覺得挺有趣的例子。如果在集合裡面有一顆 nan,先不管為什麼集合裡面會偷跑 nan 進去,要如何把它拿掉?前面我們學過 .remove() 或 .discard() 方法:
>>> s1 = {9, 5, 2, 7, float('nan')}
>>> s1
{2, 5, nan, 7, 9}
>>> s1.remove(float('nan'))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: nan
哇!因為 nan 不等於任何東西,所以 .remove() 方法沒辦法比對到這個元素,所以就出現找不到元素的 KeyError 錯誤訊息。基本上不管是 .remove() 或 .discard() 都沒辦法處理。有幾種解法,例如可以先把集合轉成串列再處理,或是利用集合推導式來過濾掉 nan:
>>> s1 = {9, 5, 2, 7, float('nan')}
>>> s2 = {item for item in s1 if item == item}
>>> s2
{9, 2, 5, 7}
冷凍集合?
我先承認,冷凍集合這中文翻譯不太好,但我也找不到更好�的翻譯,我就還是用英文 frozenset 吧。frozenset 從字面上看可以猜的出來它是一種集合,也是一種內建的資料結構。frozenset 沒有像一般的集合可以用 { } 的字面值方式來建立,只能透過 frozenset() 函數搭配可迭代物件:
# 餵給它個串列
>>> fs1 = frozenset([9, 5, 2, 7])
>>> fs1
frozenset({9, 2, 5, 7})
# 字串也行
>>> fs2 = frozenset('hello')
>>> fs2
frozenset({'l', 'h', 'e', 'o'})
跟一般的集合最大的差別就是它是不可變的(所以才叫它 frozen),那些可以用來增加、刪除或修改集合裡的元素的方法都不能用:
>>> fs1 = frozenset([9, 5, 2, 7])
>>> fs1.add(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'add'
>>> fs1.clear()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'clear'
因為 frozenset 是不可變的,所以它是一種可雜湊物件,如果要拿來當字典的 Key 也是沒問題的。