物件導向程式設計 - 進階篇

雖然大家都說 Python 是一款很容易學習的程式語言,它的語法的確寫起來很簡單,不過在這些簡單的語法背後,Python 做了不少有趣的事,這些細節我相信在平常的工作大概都是用不上的,知道這些細節的好處是以後在看待 Python 的時候會有完全不同的觀點。
這個章節的內容比較難一點,所以要先跳過這章節也可以,或是等過陣子對 Python 更熟悉之後再回來看也行。既然是進階篇,我們就先從最基本但可能有點複雜的描述器開始吧!
描述器
在 Python 的物件導向世界裡,當我們試著執行 kitty.sleep() 方法或是印出 kitty.age 屬性的值的時候,背後的運作機制可能比你想像中的複雜一些。
Python 有個叫做「描述器(Descriptor)」的設計,這是一個我認為很有趣的功能,如果只是寫一些簡單的程式或只是拿 Python 來做網站的話,大概用不上它。嗯...也不是用不上,如��果我們用網站開發框架像是 Django 做網站的時候,用到描述器的頻率還滿高的,只是你可能不知道它就是描述器而已。描述器可以讓我們在讀取或設定物件身上的屬性或執行方法的時候在背後偷偷做一些事情,同時它也是很多我們現在看起來很理所當然的功能的基礎。
使用情境
看一下這段程式碼:
class Cat:
def __init__(self, name, age):
self.name = name
self.age = age
kitty = Cat("凱蒂", 18)
這程式碼看起來沒什麼難度,來試用看看這個類別:
>>> nancy = Cat("南茜", -100)
>>> nancy.age
-100
咦?年齡怎麼可以是負的,這樣不行,來加個檢查:
def __init__(self, name, age):
if age < 0:
raise ValueError("年齡不能為負數")
self.name = name
self.age = age
這樣應該就沒問題了吧!嘿嘿,還記得我們在上個章節才介紹過 Python 並沒有真正的私有(Private)屬性,這裡只有在 __init__() 裡面做檢查,所以我可以一開始先乖乖的設定一個正常的數值,後續再改 age 屬性的值,像這樣:
>>> nancy = Cat("南茜", 10)
>>> nancy.age = -120
>>> nancy.age
-120
基本上是躲不掉啦。這時候就是描述器登場的時候了,描述器有分為資料描述器(Data Descriptor)和非資料描述器(Non-Data Descriptor),先不要在意這兩個名詞有什麼不同,待會你就會知道了,我們慢慢看下去...
非資料描述器
首先,所謂的「描述器」,在 Python 就只是個普通的類別而已,只是這個類別裡剛好實作了幾個魔術方法。先從最簡單的開始看:
class AgeValue:
def __get__(self, obj, obj_type):
return 18
這裡的 AgeValue 就�只是普普通通的類別,上層也沒有繼承其他神奇的類別,只是有實作了 __get__() 方法,這個方法不複雜,就只是先讓它固定回傳數字 18。__get__() 方法裡面的參數晚點再做說明,但光是這樣它就可以當做一個描述器。描述器的使用方法很簡單:
class Cat:
age = AgeValue()
我在 Cat 類別裡面定義了 age 屬性,一般可能就直接指定一個值給它,但這次是指定一個 AgeValue 類別所產生的「實體」給它,注意,是實體,不是類別喔。這樣一來,神奇的事情就發生了:
>>> kitty = Cat()
>>> kitty.__dict__
{}
>>> kitty.age
18
在前面章節曾經提過,當透過 . 的方式在找屬性的時候,首先會找這顆物件身上的字典是不是有這個屬性,如果沒有,會再往它的所屬類別找。在 Cat 類別的確有找到 age 屬性沒錯,而它就只是 AgeValue 類別的實體而已,為什麼它會回傳 18?
這是因為這個實體實作了 __get__() 方法,當透過 . 的方式存取屬性或方法的時候,如果這個值剛好是某個類別的實體,就會看看這個實體有沒有實作 __get__() 方法。如果有,Python 就會呼叫這個方法,然後就可以看到我們回傳的數字 18。
不信的話我再做個實驗,我刻意把 AgeValue 的 __get__() 方法拿掉,像這樣:
class AgeValue:
pass
class Cat:
age = AgeValue()
執行之後就會發現它就只是個普通的物件而已:
>>> kitty = Cat()
>>> kitty.age
<__main__.AgeValue object>
所以,魔法就在於這個類別有實作 __get__() 方法,當我們用 . 的方式存取這個屬性的時候,Python 就會去呼叫這個實體身上的 __get__() 方法。
在 __get__() 方法的三個參數分別是:
self:這個self指的是AgeValue這個類別的實體,不是kitty這個實體喔!obj:承上,這個參數才是kitty實體。obj_type:這個描述器掛在哪個類別裡,以上面的例子來說就是Cat。
待會我們還會看到描述器的其他方法,如果描述器只有實作 __get__() 方法的時候,我們稱它為「非資料描述器」(Non-Data Descriptor),它只能讀取屬性的值,但沒有寫入功能。
沒有寫入功能?誰說的:
>>> kitty = Cat()
>>> kitty.age = 1000
>>> kitty.age
1000
你看,這樣不就行了嗎?你誤會了,以結果來看的好像是可以寫入,事實上這個動作跟描述器無關,這只是在這顆 kitty 物件的字典裡加了一個 age 屬性而已,看看它的 .__dict__ 屬性就知道了:
>>> kitty.__dict__
{'age': 1000}
如果要讓描述器有寫入功能,我們就得要實作另一個方法了。
資料描述器
如果我們在 AgeValue 這個描述器裡面實作了 __set__() 方法,故事就會變的不一樣了:
class AgeValue:
def __init__(self, age=0):
self._age = age
def __get__(self, obj, obj_type):
return self._age
def __set__(self, obj, value):
if value < 0 or value > 150:
raise ValueError("年齡超過範圍")
self._age = value
class Cat:
age = AgeValue()
這裡我加上了 __init__() 方法讓我們有機會可以掛上這個描述器的時候順便設定初始的年齡,不過這裡的重點在於 __set__() 方法,裡面的參數跟 __get__() 差不多,self 指的也是描述器的實體,obj 才是這個物件本身,value 則是要設定的值。這個方法不像 __get__() 還有 obj_type 參數,但想想也合理,畢竟我們要設定的值就是這顆物件的屬性,跟 obj_type 沒什麼關係。
在 __init__() 方法裡也可以看到我暫時先把傳進來的 age 屬性存放在 AgeValue 的實體的 _age 屬性裡,這樣在設定屬性的時候就不會直接寫入 kitty 物件的 .__dict__ 裡。雖然這樣的寫法會有別的問題,不過我們晚點再討論。
另外,在 __set__() 裡我順便做了個簡單的檢查,如果年齡不在設定的區間裡就會丟出錯誤訊息。來試用看看:
>>> kitty = Cat()
# 一開始身上什麼都沒有
>>> kitty.__dict__
{}
# 透過描述器取得 age 屬性
>>> kitty.age
0
# 設定 age 屬性
>>> kitty.age = 18
>>> kitty.__dict__
{}
>>> kitty.age
18
# 超過範圍
>>> kitty.age = 1000
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/private/tmp/tt.py", line 10, in __set__
raise ValueError("年齡超過範圍")
ValueError: 年齡超過範圍
剛才我們做 kitty.age = 18 時候是直接寫進 kitty 物件的 .__dict__ 屬性裡,但有了 __set__() 方法之後,一樣的操作會發現它並沒有直接寫入 .__dict__ 裡,而是透過描述器把值寫到某個地方,以我上面的範例來說,是寫入描述器裡的 _age 屬性。
跟剛才的「非資料描述器」比起來,這種有實作 __set__() 方法或是待會就會介紹到的 __delete__() 方法的描述器稱之「資料描述器」(Data Descriptor)。雖然並沒有規定資料描述器一定需要實作 __get__() 方法,但除非有什麼特別的目的,例如想做到只寫入而不讀取屬性,不然通常都會一併實作 __get__() 方法。
剛才講到,如果只有實作 __get__() 方法就是一個「非資料描述器」,讀取屬性沒問題,但寫入的時候因為沒有 __set__() 方法,所以它會直接寫到那顆物件的 .__dict__ 裡。當再次讀取屬性的時候由於 __dict__ 的優先順序比較高,所以原本實作的 __get__() 方法就用不上了。但「資料描述器」就不同了,如果那個屬性是資料描述器,不管是讀取或寫入就都��不會讀取物件的 __dict__ 屬性了:
class UselessValue:
def __set__(self, obj, value):
pass
class Cat:
age = UselessValue()
這裡我做了個完全沒用的描述器類別 UselessValue,裡面只放了 __set__() 方法而且故意什麼事都不做,就當個開開心心的小廢物。接著我們來試試看:
>>> kitty = Cat()
>>> kitty.age
<__main__.UselessValue object>
# 設定 age 屬性
>>> kitty.age = 100
>>> kitty.age
<__main__.UselessValue object>
# __dict__ 還是空的
>>> kitty.__dict__
{}
可以看到不管是讀取或是寫入,都是直接操作描述器裡的值,而不是物件的 .__dict__ 屬性。也就是說,資料描述器會遮蔽(Shadow)物件的 __dict__,非資料描述器就沒這特性。
看到這裡,你可能會想說寫個描述器還要定義這些兩個底線方法有點麻煩,這些我們平常用不到吧,這真的有需要學嗎?如果你有使用 Django 或 Flask 框架,在操作資料庫的時候通常都會使用 ORM(Object Relational Mapping)來操作資料表,你應該會看到像這樣的寫法:
class Book(models.Model):
title = models.CharField(max_length=100)
page = models.IntegerField()
有覺得眼熟嗎?title 跟 page 這兩個屬性的寫法跟我們剛剛寫的描述器有點像吧?是的,這些就是描述器沒錯。至於為什麼這樣就能透過 .title 或 .page 來操作資料表,這就是 CharField() 跟 IntegerField() 這兩個類別裡的魔法了。
好啦,我們要回來面對該面對的問題了...
所以,值要存在哪裡?
在上面的範例中,不管是 __get__() 還是 __set__() 方法,我都是直接在 self 加上 ._age 屬性,但這 self 指的是描述器的實體,並不是我們要設定的物件,這可能會有一些問題:
# 先做出 kitty 跟 nancy 兩個物件
>>> kitty = Cat()
>>> nancy = Cat()
# 讀取以及設定 kitty 的 age 屬性,看起來一切正常
>>> kitty.age
0
>>> kitty.age = 18
# 但是 nancy 的 age 屬性也被設定成 18 了
>>> nancy.age
18
# 甚至連之後產生的物件也是...
>>> lucy = Cat()
>>> lucy.age
18
如果你從上個章節看到這裡,應該可以也不難推敲出為什麼是這個結果了。age 就只是 Cat 類別的屬性。這個屬性就是一個描述器類別所建立的實體而已,所以不管是哪個物件,都會指向同一個 age,改一個等於全部 Cat 類別所建立的實體都會跟著改。這是不是你想要的結果?我不確定,但如果不是的話,那可能得另外找地方存這個屬性的值。既然 self 不能存,那存在 obj 裡如何?我們來試試看:
class AgeValue:
def __get__(self, obj, obj_type):
return getattr(obj, '_age', 0)
def __set__(self, obj, value):
if value < 0 or value > 150:
raise ValueError("年齡超過範圍")
obj._age = value
class Cat:
age = AgeValue()
因為 obj 參數指的就是那顆物件(例如 kitty 或 nancy)本身,所以把屬性存到 obj 裡,等於是把屬性存進那顆物件的 __dict__ 裡:
# 先做出兩個 Cat 類別的實體
>>> kitty = Cat()
>>> nancy = Cat()
# 調整其中一個的 age 屬性
>>> kitty.age = 18
>>> kitty.age
18
# 另一個的 age 屬性不受影響
>>> nancy.age
0
>>> nancy.age = 20
# 來看看這兩個物件的 __dict__
>>> kitty.__dict__
{'_age': 18}
>>> nancy.__dict__
{'_age': 20}
這樣屬性的確就不會混在一起了。
但這樣的寫法有另外的問題,就是我們在 Cat 類別裡面寫死了屬性的名稱,它們目前都叫做 _age,這樣如果在同一個類別重複使用的時候:
class Cat:
age1 = AgeValue()
age2 = AgeValue()
這樣會造成一些麻煩:
>>> kitty = Cat()
# 設定 age1 屬性,一切看起來正常
>>> kitty.age1 = 18
>>> kitty.age1
18
>>> kitty.__dict__
{'_age': 18}
# 因為 age2 也是去存取 _age 屬性...
>>> kitty.age2
18
>>> kitty.age2 = 20
>>> kitty.age1
20
>>> kitty.__dict__
{'_age': 20}
也就是不管是 .age1 還是 .age2,它們都是存在 ._age 屬性裡。
好吧,我來準備一個字典來放這些屬性好了:
class AgeValue:
def __init__(self):
self.props = {}
def __get__(self, obj, obj_type):
return self.props.get(id(obj), 0)
def __set__(self, obj, value):
if value < 0 or value > 150:
raise ValueError("年齡超過範圍")
self.props[id(obj)] = value
class Cat:
age1 = AgeValue()
age2 = AgeValue()
我在描述器的實體裡,也就是 self 裡面,準備了一個空的字典 props 來存放這些屬性,在前面章節曾經介紹過在 Python 並不是所有的物件都能拿來當字典的 Key,所以我就先用 id(obj) 算出來的結果來當 Key,雖然有點醜而且不容易被人眼辨識,但暫時可以解決上面的問題。
不過也是可以用別的東西來當 Key...
描述器的屬性名稱
如果不喜歡 id() 函數算出來的數字當 Key 的話,也可以在設定描述器的時候,順便也主動帶個值進來當做屬性名稱:
class AgeValue:
def __init__(self, prop_name):
self.props = {}
self.prop_name = "_" + prop_name
def __get__(self, obj, obj_type):
return self.props.get(self.prop_name, 0)
def __set__(self, obj, value):
if value < 0 or value > 150:
raise ValueError("年齡超過範圍")
self.props[self.prop_name] = value
這裡多帶了一個 prop_name 參數,而且我刻意多加一個底線 _ 是為了避免跟屬性名稱衝突而造成不必要的麻煩。這樣就可以把在設定描述器的時候一起設定屬性名稱:
class Cat:
age1 = AgeValue("age1")
age2 = AgeValue("age2")
這樣沒什麼問題,只是明明都知道屬性名稱叫 age1,還得每次再手動寫一次 "age1" 就有點囉嗦。在 Python 3.6 之後,描述器多了一個新的魔術方法叫做 __set_name__(),這個方法會在描述器被設定的時候被呼叫,而且還能自動取得那個屬性的名字,我們可以把上面的例子改寫成這樣:
class AgeValue:
def __init__(self):
self.props = {}
def __set_name__(self, obj_type, name):
self.prop_name = "_" + name
# ... 略 ...
這樣就不用每次都手動傳入屬性名稱,它會自己抓到屬性的名字,用起來就方便多了。
刪除屬性
描述器的功能不只有存取屬性,還有刪除屬性的功能。當使用 del 關鍵字要刪除某個物件身上的屬性的時候,像這樣:
del kitty.age
如果剛好這個 .age 屬性也是一個描述器的話,在屬性被刪除的時候就會觸發描述器的 __delete__() 方法:
class AgeValue:
# ... 略 ...
def __delete__(self, obj):
print("我被刪掉囉!")
del self.props[self.prop_name]
class Cat:
age = AgeValue()
來試試看:
>>> kitty = Cat()
>>> kitty.age = 18
>>> kitty.age
18
# 刪除屬性
>>> del kitty.age
我被刪掉囉!
>>> kitty.age
0
因為 kitty 物件身上的 age 屬性剛好是一個描述器的實體,當我們使用 del 關鍵字刪除這個屬性的時候,所以就觸發了 __delete__() 方法。
函數與方法
我們在前面章節介紹過函數與方法的差別,但你有沒想過為什麼同樣的一個函數,如果透過實體呼叫的時候,Python 會幫我們把實體本身當做第一個參數帶進去給 self,但透過類別呼叫就只是一般的函數呢?這就是描述器做的好事。
我這裡直接借用 Python 官方文件的範例再稍微調整一下:
class Method:
def __init__(self, fn, obj):
self._fn = fn
self._self = obj
def __call__(self, *args, **kwargs):
fn = self._fn
obj = self._self
return fn(obj, *args, **kwargs)
這個 Method 是一個普通的類別,不過它多實作了 __call__() 函數。這不是什麼神奇的函數,在 Python 的類別只要有實作 __call__() 方法的話,這個類別所建立的實體就可以被「呼叫」,例如:
class Cat:
def __call__(self, *args, **kwargs):
print('meow')
kitty = Cat()
kitty() # 直接呼叫這顆物件!
然後它就會去執行 __call__() 方法。為什麼這裡需要先介紹這個 Method 類別呢?事實上在 CPython 的原始碼裡面關於「方法物件」的建立就是差不多在做類似的事。對 CPython 的原始碼有興趣的話,在 Objects/classobject.c 這個檔案裡有個叫做 PyMethod_New() 的函數:
PyObject *
PyMethod_New(PyObject *func, PyObject *self)
{
// ... 略 ...
}
你看不懂 C 語言的語法沒關係,我也看不懂,我引用這段原始碼的重點不是要看懂它,只是要跟大家說我們自己寫的 Method 類別跟 CPython 的原始碼裡的 PyMethod_New() 函數其實是在做差不多的事。正版的 CPython 實作比我們自己寫的複雜多了,但還是能猜的出來這個函數會把另一個函數以及把自己傳進去。
不過真正的有趣(或複雜?)的是接下來這個:
class Function:
def __get__(self, obj, onwer):
if obj is None:
return self
return Method(self, obj)
def __call__(self, *args, **kwargs):
print("Hello World")
看到上面的 __get__() 了嗎?就是它!因為有實作 __get__() 方法,所以 Function 就是個描述器類別,當透過類別呼叫描述器的時候,它的 obj 參數會是 None。也就是說,如果這個描述器是透過實體呼叫的話,會回傳一個 Method 的實體,並且把 obj,也就是那顆物件本身傳進去,但如果是透過類別呼叫的話,就直接回傳這個描述器本身,然後這個描述器本身又剛好有實作 __call__() 方法,所以可以被呼叫。
你可以繼續再翻一下在 CPython 原始碼專案裡的 Objects/funcobject.c 檔案,裡面有個叫做 func_descr_get() 的函數:
static PyObject *
func_descr_get(PyObject *func, PyObject *obj, PyObject *type)
{
if (obj == Py_None || obj == NULL) {
return Py_NewRef(func);
}
return PyMethod_New(func, obj);
}
上面這段跟我們的 Function 描述器類別在做差不多的事,連參數也差不多。準備好了前置作業,我們來看看怎麼使用這個描述器類別:
class Cat:
say = Function()
看到這裡應該不陌生了吧,這個 say 就是個描述器,實際來用看看:
>>> kitty = Cat()
# 透過實體呼叫
>>> kitty.say
<__main__.Method object>
>>> kitty.say()
Hello World
# 透過類別呼叫
>>> Cat.say
<__main__.Function object>
>>> Cat.say()
Hello World
看到了嗎?不管是透過類別或實體來呼叫這個 say 都可以正常運作,而且透過實體呼叫的時候,會把那顆物件本身傳進去給 self。也就是說,當我們在 Python 的類別裡用 def 關鍵字定義一個函數的時候,事實上它就是相當於建立一個描述器,而且還是非資料描述器,這就是描述器的魔法。CPython 實際的實作一定比我們的範例複雜多了,這裡我只是希望可以透過類似的模擬程式碼讓大家知道這些魔法背後的秘密。
你拿到的不是你以為的!
再來看看底下這個簡單的類別:
class Cat:
def meow(self):
print("喵!")
在上面這個範例中,我們可以說「在 Cat 類別裡有一個名為 meow() 的實體方法」,這樣的講法也沒錯,但現在大家應該也知道這個 meow() 也就只是個活在 Cat 類別裡的函數而已。
我再換個角度問:
kitty = Cat()
kitty.meow()
請問第二行的 kitty.meow() 的 .meow() 是什麼?
你可能會回答說就是定義在 Cat 類別的裡的那個方法啊,然後 Python 會把自己這顆物件當做第一個參數帶進去給它。是啦,但如果要更精準的角度來看的話,這裡的 .meow() 方法並不是我們定義在 Cat 類別裡的那個方法了。
我們在上一個小節介紹到在類別裡的函數與方法的時候,當我們執行 kitty.meow() 方法的時候,這個 .meow() 是 def 定義的,所以它本質上就是一個描述器。當執行 kitty.meow() 方法的時候,其實你執行的是這個描述器的 __get__() 函數所傳回來的那個方法,也就是一個 bound method,我再挖一點的 CPython 原始碼給大家看看:
/* Bind a function to an object */
static PyObject *
func_descr_get(PyObject *func, PyObject *obj, PyObject *type)
{
if (obj == Py_None || obj == NULL) {
return Py_NewRef(func);
}
return PyMethod_New(func, obj);
}
這個剛剛我們才看過,這就是函數物件的描述器 __get__() 方法,可以看到最後的 PyMethod_New() 會把要執行的函數 func 與那顆實體物件本身的 obj 當做參數,這個函數會回傳一個 PyMethodObject 物件。再追一下就會發現,傳回來的這顆物件的結構裡,有實執要執行的函數 im_func,也有這個函數要綁定的物件 im_self:
typedef struct {
PyObject_HEAD
PyObject *im_func; /* The callable object implementing the method */
PyObject *im_self; /* The instance it is bound to */
PyObject *im_weakreflist; /* List of weak references */
vectorcallfunc vectorcall;
} PyMethodObject;
如果你試著把這顆物件印出來,就會看到在前面曾經看到的 bound method 字樣,就是它!所以,看到這裡應該就能知道我們以為的 kitty.meow() 嚴格說來已經不是我們原本在 Cat 類別裡定義的那個 meow() 方法了,而是另一顆方法物件,這顆方法物件裡裝有 meow() 函數以及自己本身 self。
slots 其實也是描述器
在上個章節介紹到的 __slots__ 可以用來建立屬性白名單,但背後的過程也是描述器。舉例來說:
class Cat:
__slots__ = ('name', 'age')
這段程式碼是在 Cat 類別裡建立了 name 與 age 這兩個屬性,實際上發生的流程會先把原本的兩個內建屬性 __dict__ 跟 __weakref__ 給移掉,這也是由 Cat 類別所產生的物件沒有 __dict__ 屬性的原因。接著會把設定在 __slots__ 屬性裡的 name 跟 age 設定成描述器,存放在 Cat 類別裡的 __dict__ 裡,我稍微排版整理一下:
>>> Cat.__dict__
mappingproxy({
'__module__': '__main__',
'__slots__': ('name', 'age'),
'age': <member 'age' of 'Cat' objects>, # <-- 這裡
'name': <member 'name' of 'Cat' objects>, # <-- 還有這裡
'__doc__': None
})
但怎麼知道 name 跟 age 是描述器呢?我來翻 CPython 原始碼給大家看看:
static int
type_add_members(PyTypeObject *type)
{
PyMemberDef *memb = type->tp_members;
// ... 略 ...
PyObject *dict = lookup_tp_dict(type);
for (; memb->name != NULL; memb++) {
PyObject *descr = PyDescr_NewMember(type, memb);
// ... 略 ...
if (PyDict_SetDefault(dict, PyDescr_NAME(descr), descr) == NULL) {
Py_DECREF(descr);
return -1;
}
Py_DECREF(descr);
}
return 0;
}
中間的 PyDescr_NewMember() 函數就是在建立描述器,接著 PyDict_SetDefault() 函數把描述器設定在 __dict__ 裡,而這裡的 tp_members 裡面就是 __slots__ 裡設定的屬性。或是從 Python 也能看得出來:
>>> hasattr(Cat.name, '__get__')
True
>>> hasattr(Cat.name, '__set__')
True
>>> hasattr(Cat.name, '__delete__')
True
Cat 類別的 name 屬性有描述器的三個屬性,這就是個資料描述器無誤。
正因為 __slots__ 設定的屬性是資料描述器,根據前面介紹過的存取屬性的優先順序,假設我有個 Cat 類別建立的實體 kitty,當我試著存取 kitty.name 的時候,會先找描述器,透過描述器就能直接取得這個屬性的值。如果不是使用 __slots__,當找不到描述器的時候會再找物件本身的 __dict__ 字典,這過程就會慢那麼一點點,這也是為什麼使用 __slots__ 設定的屬性可以比一般的屬性的存取速度更快一點點的原因之一。
在 Python 有非常多地方都有用到描述器,只是通常不太明顯。不只是在類別裡的 def 定義方法,在上個章節我們介紹到的幾個裝飾器,例如 property、classmethod、staticmethod,如果你去翻原始碼的話,就會發現其實它們本質上也都是描述器。
如果想要往 Python 大師之路前進的話,描述器是一定得要花點時間研究一下的。一旦知道描述器的運作原理,之後再看 Python 程式碼的時候應該就會看到不同的世界。
Metaclass
雖然知名社群網站 Facebook 在 2021 年底把名字改成 Meta,但「Meta」這個詞跟它無關,這個詞是來自希臘文的「μετά」,後來被借到拉丁語最後變成英語,Meta 的意思是「超越」,所以 Metaclass 就是超越類別的類別。
這感覺有點抽象,我來舉個例子,大家現在應該都聽過 3D 印表機,我先假設 3D 印表機可以印出這個世界上所有的東西,那麼我是不是可用這台 3D 印表機再印出一台 3D 印表機呢?這種用印表機印出印表機的行為可以稱它叫 Metaprinting。同樣的概念,如果可以用程式碼產生程式碼,這就叫做 Metaprogramming。
回到物件導向的世界,如果有一個類別可以產生其他的類別,這個類別就是 Metaclass。有些人會把 Metaclass 跟繼承的上層類別搞混,這兩個是不同的東西。我再借用前面曾經用過的例子,就是 Animal、Cat 以及 kitty 這三個物件。kitty 是由 Cat 這個類別產生的實體,而 Cat 繼承自 Animal,但 Cat 不是 Animal 這個類別產生的。
在 Python 如果我們想要知道某個物件是由哪個類別產生的,在上個章節有介紹過可以用 type() 函數或是透過物件身上的 .__class__ 屬性查出來:
>>> kitty = Cat()
# 使用 type() 函數
>>> type(kitty)
<class '__main__.Cat'>
# 使用 __class__ 屬性
>>> kitty.__class__
<class '__main__.Cat'>
在 Python,類別也是物件,所以我們可以用同樣的手法來查看 Cat 類別是由哪個類別產生的:
>>> type(Cat)
<class 'type'>
>>> Cat.__class__
<class 'type'>
你會看到一個很有趣的答案,type。這個 type 就是我們常常在用的那個 type() 函數,它本質上是一個類別,之前為了不讓大家搞混,我都只用函數來稱呼它。事實上,我們很早學到可以用來轉型的 int() 跟 str() 或是 list(),這些本質上都是類別。
在 Python 裡不管是你自己寫的還是 Python 內建的類別,只要沒有特別設定 Metaclass 的話,所有的類別都是由 type 這個類別產生的,包括 type 自己也是:
# 你寫的 Cat 類別
>>> type(Cat)
<class 'type'>
# 內建的類別
>>> type(int)
<class 'type'>
>>> type(str)
<class 'type'>
# type 本身
>>> type(type)
<class 'type'>
也就是說,type 這個類別可以說是 Python 裡所有類別的 Metaclass。
雖然通常不會這樣寫,但的確是可以用 type() 來寫一個類別出來。type() 類別有三個參數,分別是類別的��名字、上層類別以及類別的屬性或方法,其中上層類別是一個 Tuple,而屬性或方法則是一個字典:
Animal = type('Animal', (), {"age": 0})
Cat = type('Cat', (Animal,), {})
上面這段程式碼跟下面這段是等價的:
class Animal:
age = 0
class Cat(Animal):
pass
其實 class 只是語法糖
如果有興趣挖 CPython 的原始碼的話,就會發現其實 class 語法背後就是用 type() 在做事情,在 CPython 的原始碼裡的 Python/bltinmodule.c 檔案裡有個 builtin___build_class__() 函數,就是在做這件事。
舉例來說,假設我有個 Cat 類別在 Python 是這樣定義的:
class Cat:
age = 0
def meow(self):
print("喵~")
實際上 builtin___build_class__() 函數把這段程式碼拆解成兩部份,分別是類別本身以及其他部份的定義。類別的定義會使用 type() 函數來建立,就像我們上面的做法一樣,如果有上層類別的話會把它放在 type() 函數的第二個參數裡,而第三個參數就有趣了,Python 是怎麼做到把 age = 0 以及 def meow(self) 函數轉換成字典的呢?在原始碼裡有一段寫著:
ns = PyDict_New();
可以看到這裡先建了一個空的字典,這裡的 ns 是 namespace 的縮寫。接著後面有一段:
cell = _PyEval_Vector(tstate, (PyFunctionObject *)func, ns, NULL, 0, NULL);
這裡差不多就是做了 Python 的內建函數 exec() 函數的事情,它會把類別裡的所有定義,像是變數或函數的宣告,轉換成以字典型式並存進 ns 變數裡。我用 Python 模擬一下:
ns = {}
code = """
age = 0
def meow(self):
print("喵~")
"""
exec(code, None, ns)
這時如果印出 ns 的話,你會看到:
>>> ns
{'age': 0, 'meow': <function meow>}
有了類別的名稱、上層類別以及屬性或方法的字典之後就可以準備來建立類別了:
PyObject *margs[3] = {name, bases, ns};
cls = PyObject_VectorcallDict(meta, margs, 3, mkw);
那個 margs 變數裡面就是我們剛剛準備好的三個參數,接著就是建立類別了。如果你再繼續追進 Objects/typeobject.c 檔案的話,你應該會看到它把我們傳進去的那個字典設定成類別的 __dict__ 屬性,並且會呼叫 __new__() 跟 __init__() 函數等行為。如果沒有上層類別的時候,Python 會自動幫我們設定上層類別是 PyBaseObject_Type,也就是我們前面提到的 object 類別。雖然追原始��碼的過程挺有趣,但再追下去就超過這本書的範圍了,我就先在這裡打住了。
這就是在 Python 世界裡關鍵字 class 背後的秘密,也就是說 class 語法其實就是 type() 的語法糖而已。
如果看懂上面這段內容的話,可以猜猜看下面這段程式碼的答案是什麼:
>>> isinstance(object, type) # 這會印出什麼?
>>> isinstance(type, object) # 反過來的話,這又會印出什麼?
兩個答案都是 True,但為什麼?
剛剛提到不管是自己寫的類別或是內建的類別,包括 type 類別本身,都是 type 這個類別生出來的,所以 isinstance(object, type) 會得到 True 比較不意外。
但為什麼第二個也是 True?在 Python 3 不管是貓類別還是狗類別,所有類別的最上層類別都是 object 類別,也就是說 isinstance(任何東西, object) 這句永遠都會成立。正因為在 Python 所有的東西都是物件,type 類別本身也是物件,所以 isinstance(type, object) 也會得到 True。
不知道大家看到這裡會不會覺得有點頭暈呢?我是覺得挺好玩的 :)
建構子?
在上個章節我們曾經介紹過 __init__() 方法,我有特別提到它不是「建構子」,它就只是做實體的初始化而已。在 Python 裡比較接近其他程式語言建構子的設計,是另一個魔術方法:__new__()。我們來看看這個是怎麼運作的。
一樣用個簡單的例子:
class Cat:
pass
kitty = Cat()
在 Python 的類別也是物件,在前面曾經提過,當執行某個物件的時候,Python 會呼叫這顆物件身上的 __call__() 方法,所以我們就去追追看類別的 __call__() 到底在做些什麼事。怎麼追?我們前面提到所有的類別都是 type 類別的實體,所以這個 __call__() 方法應該是定義在 type 類別裡才是,所以我去挖一下 type 類別的定義,原始碼在 Objects/typeobject.c:
PyTypeObject PyType_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
// ... 略 ...
"type", /* tp_name */
0, /* tp_hash */
(ternaryfunc)type_call, /* tp_call */
// ... 略 ...
};
在原始碼的註解可以看到這個物件的名字是 "type",這也是為什麼印出來的時候會有 "type" 字樣的原因。接著還有一段 type_call 的函數,這個函數就是 type 類別的 __call__() 方法,我們來看看這個 type_call 在做些什麼事,繼續往下追,在同一個檔案裡就能找到。type_call() 這個函數的行數稍微多一點,我們挑�重點來看:
if (type->tp_new == NULL) {
_PyErr_Format(tstate, PyExc_TypeError,
"cannot create '%s' instances", type->tp_name);
return NULL;
}
obj = type->tp_new(type, args, kwds);
看到了嗎?會在這裡呼叫 tp_new() 函數,這個就是會呼叫類別裡的 __new__() 函數。再往下一點,寫了一段有意思的註解:
/* If the returned object is not an instance of type,
it won't be initialized. */
if (!PyObject_TypeCheck(obj, type))
return obj;
也就是說,如果透過 __new__() 函數所產生的物件跟這個類別不是同一個類別的話,接下來的初始化就不會進行。待會我們來寫個簡單的例子來驗證這個說法,再繼續往下看一點:
type = Py_TYPE(obj);
if (type->tp_init != NULL) {
int res = type->tp_init(obj, args, kwds);
// ... 略 ...
}
return obj;
這裡的 tp_init(),就是我們熟悉的 __init__() 函數啦。也就是說,當我們呼叫 Cat 類別的時候,會先執行 __new__() 函數建立實體,然後再呼叫 __init__() 函數,把這個剛剛建立的實體跟其他參數傳入並進行初始化。所以實際上在建立物件的地方是 __new__() 函數,就是 Python 裡面最接近建構子的方法了。
來做個簡單的實驗:
class Cat:
def __new__(cls):
print("被 New 了")
return super().__new__(cls)
def __init__(self):
print("被 Init 了")
kitty = Cat()
執行之後就會發現,__new__() 函數會先被呼叫,接著才是 __init__() 函數。這就是 Python 物件的建立流程。但剛剛程式碼裡也有提到,如果在 __new__() 的過程中所產生的物件跟這個類別不是同一個類別的話,初始化就不會進行,我們來看看這個例子:
class Dog:
pass
class Cat:
def __new__(cls):
print("被 New 了")
return Dog() # 故意在這裡做一隻 Dog
def __init__(self):
print("被 Init 了")
kitty = Cat()
執行之後就會發現,__new__() 函數會被呼叫,但 __init__() 函數卻不會跟著執行。但這樣的決策好像也可以理解,畢竟在 Cat 類別裡要幫 Dog 類別產生的物件做初始化,怎麼想都不太對勁。
Python 的魔術方法
所謂的魔術方法(Magic Methods),就是 Python 裡面的特殊方法,這�些方法通常都是以兩個底線開頭跟結尾的,所以通常會稱它們為 Double Underscore 方法,這名字有點長,所以常聽到會被唸成 dunder 方法。我們已經看到不少例子了,從一般常見的 __init__() 到描述器的 __get__() 等方法,這些都是。這些魔術方法的名稱都是固定的,我們只要實作這些方法,Python 會在適當的時機呼叫這些方法。
也正因為這種頭尾兩個底線的命名風格通常都是 Python 內部使用的,所以在我們自己的程式碼裡就盡量不使用類似的方式命名,以免跟 Python 內建的功能衝突。就算現在 Python 本身還沒有實作的 dunder 方法也不要這麼做,你不會知道將來新版的 Python 會不會再加更多新的魔術方法就剛好跟你寫的方法同名,要是真的發生的話,這個錯誤會很不好抓。
有些魔術方法在前面的章節介紹過了,我們先速快的回顧一下:
__contains__()是用來判斷物件是否包含某個元素,這會在使用關鍵字in的時候被呼叫。__new__()跟__init__(),這是用來建立物件跟初始化物件的方法。__get__()、__set__()、__delete__()、__set_name__(),這是描述器的方法。__call__()當物件被當成函數呼叫的時候會執行它。
接著我們來看看其他常見的魔術方法。
物件看起來的樣子
我相信大家一定用 print() 函數印過東西吧,當我們使用 print() 函數要印出一顆物件的時候,通常會看到一串看起來像是記憶體位置的字串
>>> kitty = Cat("Kitty")
>>> print(kitty)
<__main__.Cat object at 0x102762720>
這其實是 Python 的魔術方法 __str__() 的預設行為,印出來的這些看起來像記憶體位置的資訊對我們一般人來說沒什麼意義。如果想讓印出來的東西看起來更適合人類閱讀,可以實作 __str__() 方法來改變這個行為:
class Cat:
def __init__(self, name):
self.name = name
def __str__(self):
return f"Hello {self.name}"
這樣一來透過 print() ��函數印出來的效果就好多了:
>>> kitty = Cat("Kitty")
>>> print(kitty)
Hello Kitty
__str__() 方法的回傳值規定必須是字串,如果不是字串在被印出來的時候會出現 TypeError。__str__() 方法不只是在 print() 函數裡會被呼叫,當我們在使用 str() 以及 format() 函數,包括在 Python 超好用的「F 字串」的時候都被呼叫:
>>> str(kitty)
'Hello Kitty'
另一個跟 __str__() 有點類似的魔術方法是 __repr__(),其中 repr 是 representation 的意思,這個方法通常是給開發者用來偵錯的,所以在實作這個方法的時候通常會回傳更詳細的資訊:
class Cat:
def __init__(self, name):
self.name = name
def __repr__(self):
return f"Cat(name={self.name})"
這裡我連這個物件的類別資訊也一起印出來。使用的時候跟 __str__() 差不多:
>>> kitty = Cat("Kitty")
>>> print(kitty)
Cat(name=Kitty)
同時,跟 str() 一樣,當呼叫內建函數 repr() 的時候,也會呼叫 __repr__() 方法:
>>> repr(kitty)
'Cat(name=Kitty)'
這兩個魔術方法的目的都差不多,都是要讓物件的資訊以更容易被閱讀的方式呈現給我們看,其中 __str__() 是給一般人看的,所以通常裡面會放一般人比較能理解的資訊,而 __repr__() 是給開發者看的,所以通常會放一些只有開發者比較需要的資訊。不過這並沒有強制規定,你可以根據自己的需求來決定要怎麼實作這兩個方法。
如果在同一個類別裡,__str__() 跟 __repr__() 這兩個方法都有實作的話,像這樣:
class Cat:
def __init__(self, name):
self.name = name
def __str__(self):
return f"Hello {self.name}"
def __repr__(self):
return f"Cat(name={self.name})"
這樣在印東西的時候,要聽誰的?這得看你怎麼印:
print()、str()、format()以及 F 字串會聽__str__()的。repr()這個函數會聽__repr__()的。
另外,如果你在 REPL 環境下直接輸入物件的話,會看到跟 repr() 一樣的效果:
>>> kitty = Cat("Kitty")
>>> print(kitty)
Hello Kitty
>>> kitty
Cat(name=Kitty)
想想也合理,畢竟會進到 REPL 環境直接操作的人應該都是開發者吧。
如果只有實作 __repr__() 但卻沒有實作 __str__() 方法,這樣 print() 的時候會出現什麼?關於 __str__() 方法,官方手冊上有寫到這一行:
The default implementation defined by the built-in type object calls
object.__repr__().
也就是說,其實在 Python 裡的所有物件的 __str__() 的預設行為就是呼叫 __repr__()。所以如果有實作自己的 __str__() 方法,那就聽 __str__() 的,沒有的話就會呼叫 __repr__() 方法。這段在 CPython 的原始碼也有提到,而且還算容易懂:
static PyObject *
object_str(PyObject *self)
{
unaryfunc f;
f = Py_TYPE(self)->tp_repr;
if (f == NULL)
f = object_repr;
return f(self);
}
剛好 Python 所有物件的 tp_repr 就是 object_repr() 函數,也就是 __repr__() 方法。
所以,如果你是開發者(你都在看這本書了,應該是吧?),在開發的過程中想印點東西給自己看,實作 __repr__() 方法,如果是要輸出給一般使用者看的,實作 __str__() 方法。
可迭代物件
我們從很前面的章節就曾經提過「可迭代物件」這個名詞,大部份時候都是把它丟進 for 迴圈把裡面的元素一個一個印出來,或是透過推導式產生出新的資料。但它到底是怎麼運作的��呢?
這裡有三個有點類似的名詞要先介紹一下:
- Iteration,「迭代」,名詞,指的是遍歷某個物件裡面所有元素的過程。
- Iterable,「可迭代的」,形容詞,是指可以被進行迭代的物件,之前提到的「可迭代物件」就是指它。
- Iterator,「迭代器」,名詞,有點像是一個容器,我們可以用特定的方法遍歷這個容器中的每個元素。
用一般人可能比較容易理解的例子,如果把「迭代器」比喻成食物的話,「可迭代物件」就是指可以吃的東西,而「迭代」就是一口一口把東西吃掉的過程。
可迭代物件不一定是迭代器,就像可以吃的東西不一定是食物一樣,例如 Python 的串列可以進行迭代的行為,所以串列是一種可迭代物件,但它不是一個迭代器。
根據 Python 對迭代器的定義,只要有實作「迭代器協議(Iterator Protocol)」的物件,就能被稱之迭代器。迭代器協議的內容也很簡單,只要有實作 __iter__() 以及 __next__() 這兩個魔術方法就行了。
__iter__() 方法會回傳一個迭代器物件,而 __next__() 方法倒是沒這個限制,但通常是會回傳下一個元素(所以才叫這名字),如果沒有下一個元素了,就要丟出 StopIteration 來知會大家已經沒東西可以拿了。我們來寫一個簡單但沒什麼意義的範例:
class Cat:
def __iter__(self):
return self
def __next__(self):
return "Hello"
kitty = Cat()
因為 Cat 類別實作了迭代器協議,我們就能說 Cat 類別所產生的實體 kitty 是一個迭代器。透過 Python 內建函數 next() 可以取得「下一個」元素:
>>> next(kitty)
'Hello'
>>> next(kitty)
'Hello'
>>> next(kitty)
'Hello'
執行之後會發現每次都會印出 "Hello" 字串,這是因為 next() 函數會呼叫 kitty 物件的 __next__() 方法,而這個方法每次都會回傳 "Hello" 字串。kitty 身為迭代器它也是一個可迭代物件,所以也能被放到 for 迴圈裡:
for k in kitty:
print(k)
猜猜看這會印出什麼?它會一直不斷的在畫面上印出 "Hello" 字串,因為 kitty 物件的 __next__() 方法永遠都會回傳 "Hello" 字串,它不知道該在什麼時候停下來。如果你不小心執行了的話,可以按 Ctrl + C 中斷程式執行。
像這樣一直迭代下去會造成無窮迴圈,所以通常在 __next__() 方法裡會加上適當的條件判斷,當沒有下一個元素或是認為應該停下來時,丟出 StopIteration 讓大家知道該停下來了。我改寫一下剛才的例子:
class Cat:
def __init__(self, count):
self.count = count
def __iter__(self):
return self
def __next__(self):
self.count -= 1
if self.count < 0:
raise StopIteration
return self.count
我在 __next__() 裡加上了簡單的判斷,只要 count 數字小於 0 就丟出 StopIteration �例外。來試用看看:
>>> kitty = Cat(3)
>>> next(kitty)
2
>>> next(kitty)
1
>>> next(kitty)
0
>>> next(kitty)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/tmp/demo.py", line 11, in __next__
raise StopIteration
StopIteration
當透過 next() 得到 StopIteration 的時候就是表示「到這裡就好」,因為是例外,所以你可能想到使用�在錯誤處理章節學到的 try...except... 語法來處理一下。不過如果是在 for 迴圈收到 StopIteration 的話,不需要特別處理就會知道自己該停下來,不會出錯。
Iterator 不只可以丟進 for 迴圈轉轉轉,在串列推導式也沒問題:
>>> [c for c in Cat(3)]
[2, 1, 0]
還有還有,還記得我們前面學過「開箱(Unpacking)」的語法嗎?
>>> a, b, c = Cat(3)
>>> a
2
>>> b
1
>>> c
0
當進行開箱的時候,Python 會把可迭代物件的元素一個一個取出來。當時大家在開箱的時候可能沒注意,但現在再回頭想想,開箱語法是不是都是用在可迭代物件上呢?
現在知道 __next__() 方法是用來回傳某個值,那麼 __iter__() 是什麼用途?事實上當我們把迭代器丟進 for 迴圈、串列推導式或進行開箱的時候,這些語法都會先呼叫 __iter__() 方法取得一個迭代器物件,這個方法通常會回傳自己這顆物件,然後才接著呼叫 __next__() 方法取得下一個元素,直到沒東西可以拿出來為止。
所以,只要有實作了迭代器協議的物件,就是一個迭代器,就可以使用 for 迴圈、串列推導式、開箱等等的語法。
上面提到,只要有實作迭代器協議的就算是迭代器,那什麼是可迭代物件呢?根據 PEP 234 的記載:
- An object can be iterated over with
forif it implements__iter__()or__getitem__().- An object can function as an iterator if it implements
next().
第二條我們已經知道了,但第一條說的是只要實作了 __iter__() 或是 __getitem__() 方法的物件就可以被 for 迴圈迭代,我們就能說這個物件是「可迭代物件」。我一樣先用個沒什麼意義的例子來示範一下 __getitem__() 方法:
class Cat:
def __getitem__(self, key):
return key
這裡我只實作 __getitem__() 方法,實作了這個方法之後,我們就可以用類似串列或字典的方式來取得物件裡的元素。來試用看看:
>>> kitty = Cat()
>>> kitty["hello"]
'hello'
>>> kitty[0]
0
雖然 kitty 只是個普通的物件,但有實作 __getitem__() 方法的話,就能對這顆物件使用中括號,而中括號裡的 0 和 "hello" 就是我們在 __getitem__() 方法裡的參數 key。
不只可以像串列或字典一樣存取值,回到可迭代物件的主題,只要有實作 __getitem__() 方法的物件就能丟進 for 迴圈迭代:
for c in Cat():
print(c)
先不要急著執行喔!有沒有覺得哪裡怪怪的?是的,在上面的 __getitem__() 方法同樣沒有設定停止條件,所以這個 for 迴圈會一直執行,不斷的在畫面上印出傳進去的索引值,直到你按 Ctrl + C 終止程式為止。在前面介紹到的 __next__() 方法如果要終止是丟出 StopIteration 的例外,而在 __getitem__() 方法要做到類似的事除了丟出 StopIteration ,更常見也更合適的是丟出 IndexError 的例外,我來改寫一下剛剛的例子:
class Cat:
def __init__(self, max):
self.max = max
def __getitem__(self, key):
if key >= self.max:
raise IndexError
return key
再來試用看看:
for c in Cat(5):
print(c)
應該就會看到印出 0 到 4 的數字,for 迴圈在迭代的過程中如果遇到 StopIteration 或 IndexError 的例外並不會讓程式停下來,只會中止正在運作的 for 迴圈。
只要實作 __iter__() 或 __getitem__() 其中一個就算是可迭代物件,如果兩個都實作的話,應該聽誰的?Python 會先執行 __iter__() 方法,沒有 __iter__() 方法的話才會找 __getitem__() 方法。只是如果是走 __iter__() 路線的話,Python 就會認為這是一個迭代器,照協議規定就要實作 __next__() 方法,沒有的話會出錯。
我把這個流程判斷畫成一張圖,希望能讓大家更容易理解 Iterator 跟 Iterable 的差異:
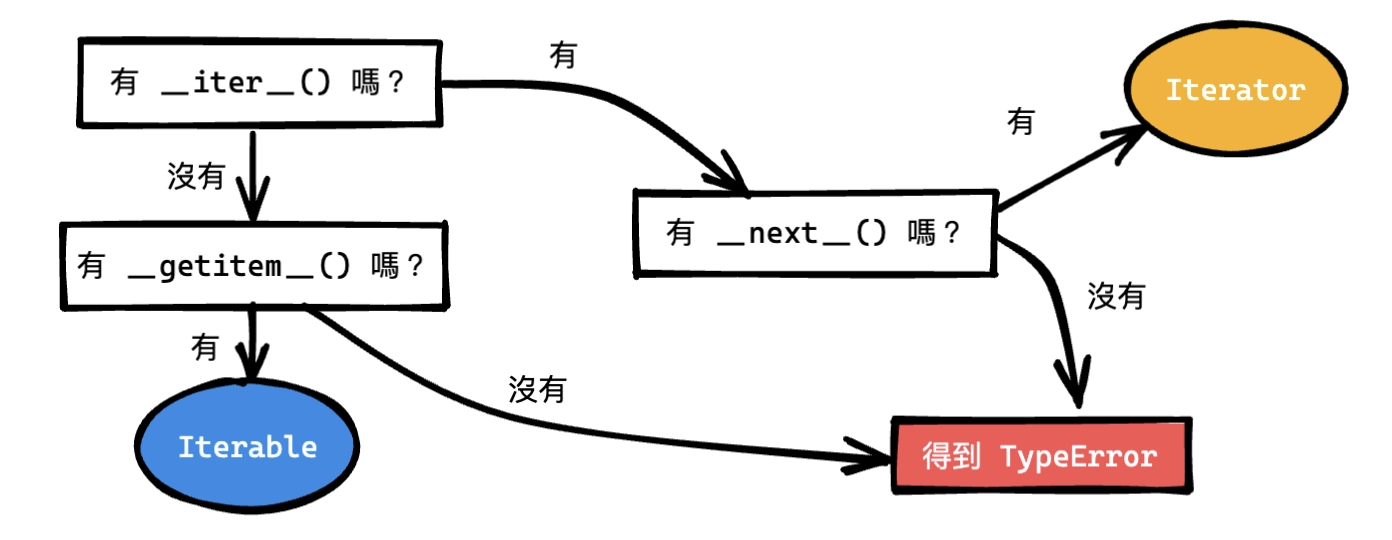
迭代器有規定要實作 __iter__() 及 __next__() 方法,所以迭代器一定是可迭代物件。相對的,可迭代物件只需要實作 __iter__() 或 __getitem__() 其中一個方法,而且不用實作完整的迭代器協議,所以可迭代物件不一定是迭代器,這就是「食物一定是可以吃的,但可以吃的不一定是食物」的概念。